
About me
I am currently working as an assistant professor, collaborating with Prof. [Zhiming Zheng] and Prof. [Wenjun Wu], at School of Artificial Intelligence, Beihang University.
I pursued my PhD from 2019 to 2024 across three prestigious institutions: Carnegie Mellon University, The Hong Kong University of Science and Technology, and Renmin University of China, studying Computer Science. At CMU, I had the privilege of working under the guidance of Prof. Min Xu. My time at HKUST was spent collaborating with Prof. Kai Chen. While at RUC, I worked closely with Prof. Jun He and Prof. Hongyan Liu from Tsinghua University. My research interests lie in the areas of multi-modal LLMs, avatars, and embodied AI.Please feel free to contact me by email (fanzhaoxinruc@gmail.com or zhaoxinf@buaa.edu.cn), if you are interested in my research.
Our team focuses on human-centric artificial intelligence, with the ultimate goal of achieving intelligence that surpasses human capabilities. Currently, our research spans three key areas: Avatar, where we study human interaction and motion from a software perspective; MLLM, where we explore human cognition and thought processes through the lens of software; and Embodied AI, where we investigate how to transfer the capabilities of avatars and LLMs in virtual environments into the real world, aiming to create robots that truly exceed human performance. Through these interconnected efforts, we strive to advance the frontier of artificial intelligence and realize the vision of superhuman intelligence.
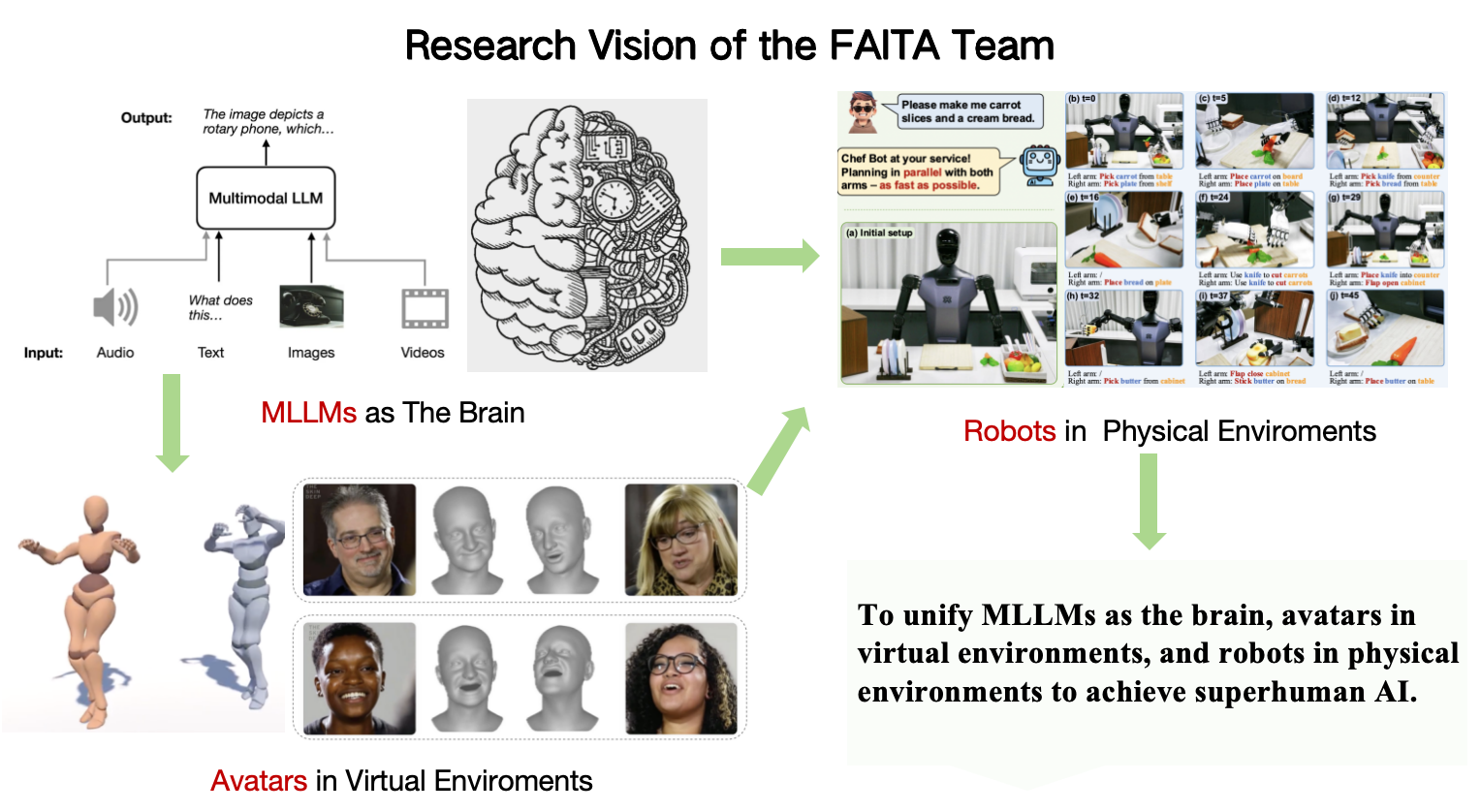
- If you are interested in becoming my student or a close collaborator, please answer the following questions before contacting me via email:
- Firstly, familiarize yourself with my research area by reading my recent papers and visiting our research group’s webpage. Research requires passion, and lack of interest may hinder persistence.
- If you are applying for a direct PhD or a combined Master’s and PhD program, it implies that you see academia as a career path. Please decide after understanding the challenges and rewards of an academic life.
- When applying for a Master’s program, I value excellent undergraduate grades, a solid foundation in mathematics, proficient programming skills, and good English proficiency.
- I hope you are optimistic and proactive, with a resilient spirit, clear logical thinking, and good teamwork skills.
- After considering these points, if you still wish to choose me as your mentor, please send your resume via email, including personal details, academic records, work or internship experiences, research experience, publications, and any other relevant information. I will respond as soon as possible.
News!
- Dec/20/2025, Congrats to Ye for his first VLA work being accepted by Neurocomputing!
- Dec/3/2025, Glad to annouce that R-FGDepth is accepted to Pattern Recongition!.
- Nov/26/2025, Congrats to Xinyu for his first theory work on pruning being accepted by Neurocomputing!
- Nov/8/2025, Glad to annouce that Monodream and Mem4d are accepted to AAAI 2026 !
- Oct/25/2025, Excited to annouce that SyncTalk++ is accepted to TPAMI !
- Oct/16/2025, Excited to annouce that AsynFusion is awarded by PRCV 2025 best student paper and CCF outstand paper!
- Sep/24/2025, Glad to annouce that 1 paper is accepted to Neurips.
- Sep/13/2025, Glad to annouce that our latest survey paper on avatars is accept to ACM Computing Surveys!.
- Sep/1/2025, Glad to annouce that 1 paper is accepted to Pattern Recognition. The impact factor of PR is 7.6 now.
- Aug/21//2025, Glad to annouce that 1 paper is accepted to PRCV 2025.
- Aug/2/2025, Excited to annouce that LongVLA is accepted to CoRL2025 !
- July/5/2025, Excited to annouce that 2 papers are accepted to ACM MM 2025 !
- June/26/2025, Excited to annouce that 2 papers are accepted to ICCV 2025 !
- June/22/2025, Glad to annouce that TBA is accepted to Pattern Recongition. Our first work on avatar security!
- June/8/2025, I am happy to serve as the Area Chair of 3DV 2026!
- May/20/2025, I am happy to serve as the Area Chair of PRCV 2025!
- May/15/2025, Excited to annouce that 2 papers are accepted to ACL 2025 !
- May/1/2025, EraseAnything is accepted to ICML 2025! Congrats to all co-authors!
- April/29/2025, GLDiTalkerg is accepted to IJCAI 2025! Congrats to all co-authors!
- March/30/2025, We are hiring RAs at HKUST! Welcome to contact us by zhaoxinf@buaa.edu.cn!
- March/21/2025, Two paper are accepted to ICME 2025. Congrats to Xukun and Zhiying!
- Feb/27/2025, Excited to annouce that 3 papers are accepted to CVPR 2025 !
- Feb/12/2025, Excited to annouce that VarGes is accepted to CVMJ. The impact factor of CVMJ is 17.3.
- Dec/1/2024, Glad to annouce that Idea-2-3d is accepted to Coling 2025 main track.
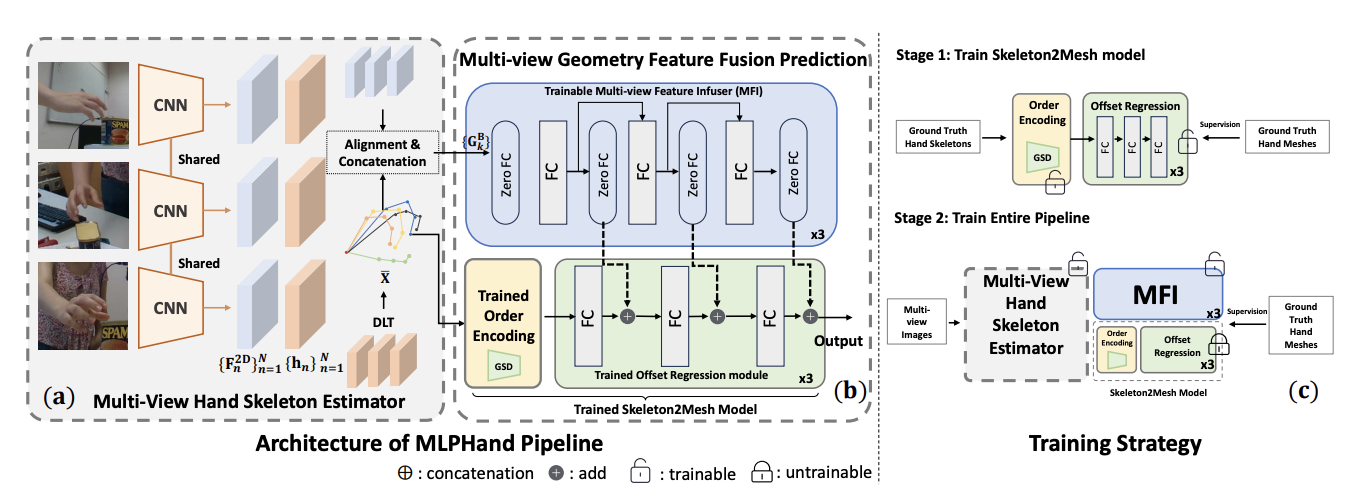
- July/1/2024, Glad to annouce that MLPHand is accepted to ECCV 2024 main track.
- April/7/2024, Excited to annouce that 5 papers are accepted to ICMR 2024.
- March/22/2024, Congrats to Han Sun for his first paper being accepted to IEEE Transactions on Instrumentation & Measurement.
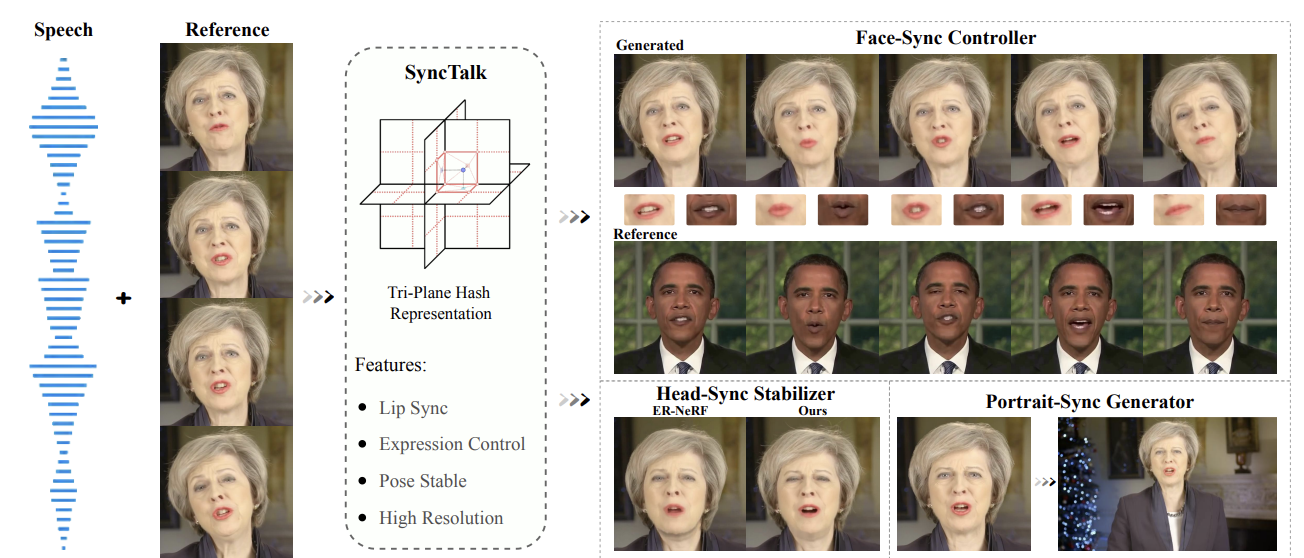
- Feb/27/2024, Glad to annouce that SyncTalk is accepted to CVPR 2024 main track.
- Dec/9/2023, Our recent paper Everything2Motion is accepted to AAAI 2024 main track and the paper FurPE is accepted to AAAI 2024 workshop. Congrats to all authors.
- Nov/17/2023, Congrats to Yixing Lu for his first paper being accepted to International Conference on Multimedia Modeling.
- Sep/21/2023, We are awarded the second prize in the National Challenge Cup! I together with Professor Li Ronghua serve as the advisors of this project.
- July/26/2023, I am thrilled to announce that our latest work, SelfTalk, has been accepted by ACM MM 2023!
- Two papers D-IF and Emo-Talk are accepted by ICCV 2023, one of the best conference in computer vision.
- Excited to annouce that one of our papers has been accepted by signal processing, IF=4.729
- Excited to annouce that one of my papers has been accepted by IJCAI 2023.
- I am honored to have returned to Carnegie Mellon University as a visiting scholar.
- One of my papers has been accepted for presentation at CVPR 2023, which is considered one of the most prestigious computer vision conferences in the world.
- I am thrilled to have had one of my papers accepted for presentation at ICRA 2023, which is a leading robotics conference.
- My research has been recognized at ECCV Workshop 2022, PRCV 2022, and ECCV 2022, all of which are highly-regarded international conferences in the field of computer vision.
- I am proud to have had a paper accepted for publication in the ACM Computing Surveys journal, which is widely considered one of the best ACM journals with an impact factor of 14.324.
- The virtual actor An-Ruohan of Psyai, which I helped to develop, performs her show daily on bilibili.
- My research has also been recognized at ICIP 2022, which is a top-tier computer vision conference with a long-standing reputation for excellence.
- I am excited to announce that one of my papers has been accepted for presentation at AAAI 2022, which is a leading artificial intelligence conference.
Working Experience
- Researcher, Psyche AI Inc (2021 - 2024)
- As a researcher at Psyche AI Inc, I am responsible for leading and overseeing various projects related to human body reconstruction, talking head technology, and 3D foundation models. In this role, I contribute my expertise in the development of innovative AI solutions that advance the field of computer vision and digital avatars.
- Technical Adviser, Xreal (2023 - 2024)
- As a Technical Adviser at Xreal, my primary focus is on the research and development of algorithms for 6D object pose estimation, point cloud completion, and 3D foundation models. Working remotely, I collaborate with a team of researchers and engineers to design and implement cutting-edge algorithms that enhance the accuracy and efficiency of computer vision systems.
- Joint Appointment Researcher, TeleAI (2024 - 2025)
- As a Joint Appointment Researche, my primary focus is on the research and development of algorithms for llm agent. During the perioad in TeleAI, I collaborate with Dr. Jian Zhao and Prof. Xuelong Li closely.
- Remote Algorithm Researcher, Xreal (2021 - 2023)
- As a Remote Algorithm Researcher at Xreal, my primary focus is on the research and development of algorithms for 6D object pose estimation, point cloud completion, and 3D foundation models. Working remotely, I collaborate with a team of researchers and engineers to design and implement cutting-edge algorithms that enhance the accuracy and efficiency of computer vision systems.
- Intern, Bytedance Inc (2020 - 2021)
- During my internship at Bytedance Inc, I gained valuable experience in the field of computer vision, specifically in the areas of 6D object pose estimation, 3D object detection, and 3D object tracking. As an intern, I actively contributed to the development of algorithms and systems, working closely with experienced professionals in the industry.
Selected Publications
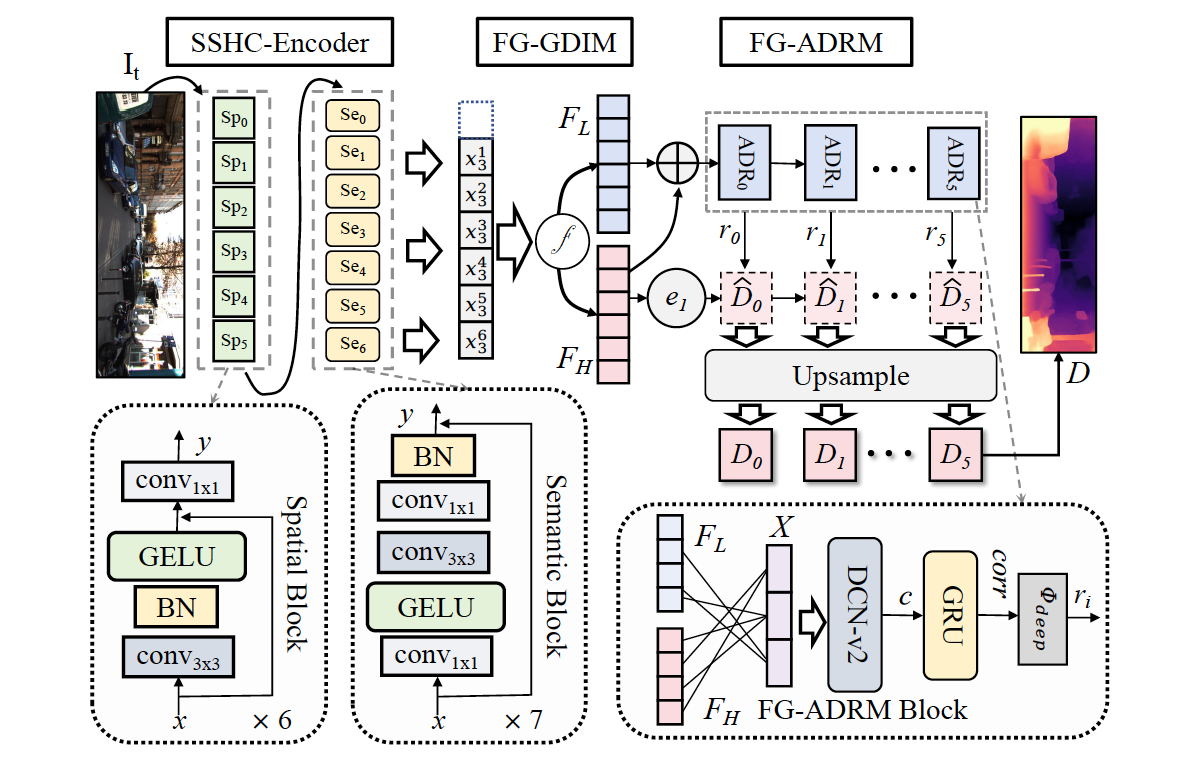
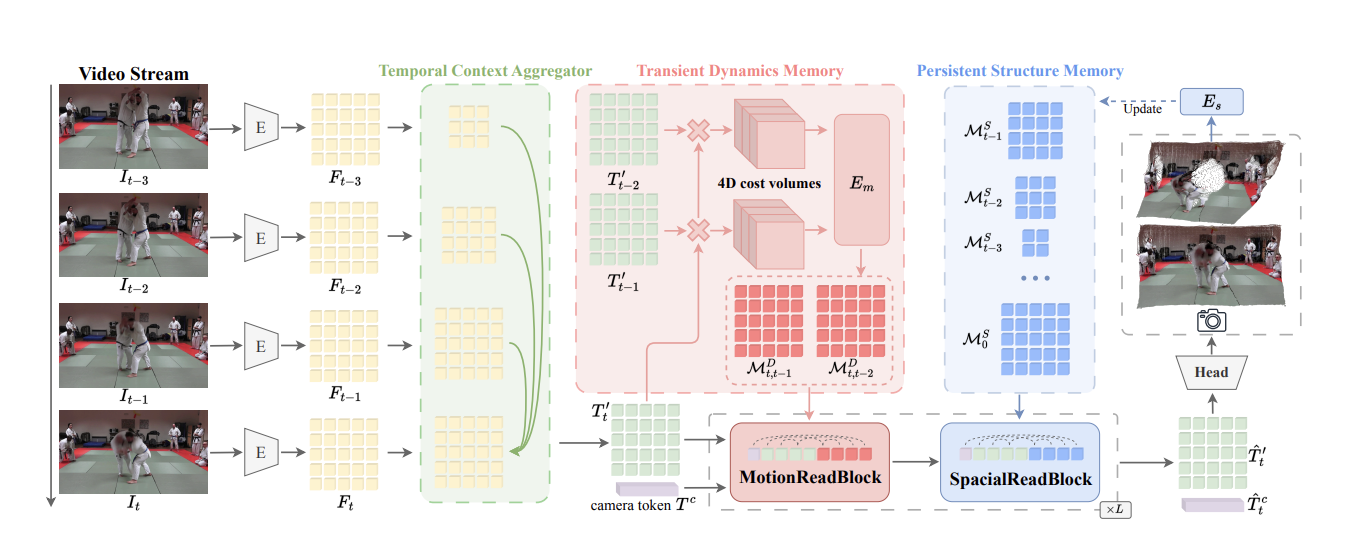

MonoDream: Monocular Vision-Language Navigation with Panoramic Dreaming
Shuo Wang, Yongcai Wang, Wanting Li, Yucheng Wang, Maiyue Chen, Kaihui Wang, Zhizhong Su, Xudong Cai, Yeying Jin, Deying Li, Zhaoxin Fan (corresponding author)
AAAI Conference on Artificial Intelligence (AAAI), 2026.
[Paper] [Code]

SyncTalk++: High-Fidelity and Efficient Synchronized Talking Heads Synthesis Using Gaussian Splatting
Ziqiao Peng, Wentao Hu, Junyuan Ma, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Hui Tian, Jun He, Hongyan Liu, Zhaoxin Fan (corresponding author)
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025.
[Paper] [Code]
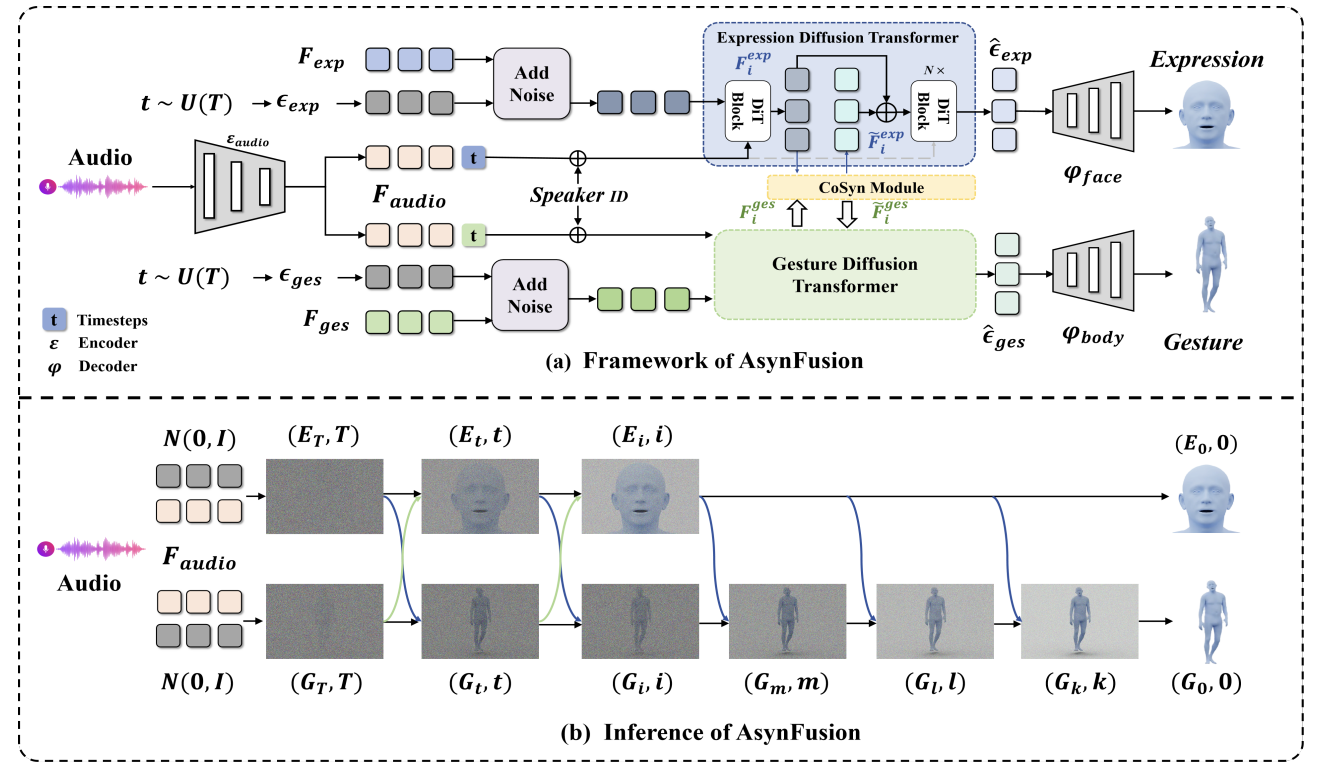
AsynFusion: Towards Asynchronous Latent Consistency Models for Decoupled Whole-Body Audio-Driven Avatars
Tianbao Zhang, Jian Zhao, Yuer Li, Zheng Zhu, Ping Hu, Zhaoxin Fan (corresponding author), Wenjun Wu, Xuelong Li
Chinese Conference on Pattern Recognition and Computer Vision (PRCV Best Student Paper& CCF outstanding Paper!), 2025.
[Paper] [Code]

Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation
Shuo Wang, Yongcai Wang, Wanting Li, Xudong Cai, Yucheng Wang, Maiyue Chen, Kaihui Wang, Zhizhong Su, Deying Li, Zhaoxin Fan(corresponding author)
Neural Information Processing Systems Conference (NeurIPS), 2025.
[Paper] [Code]
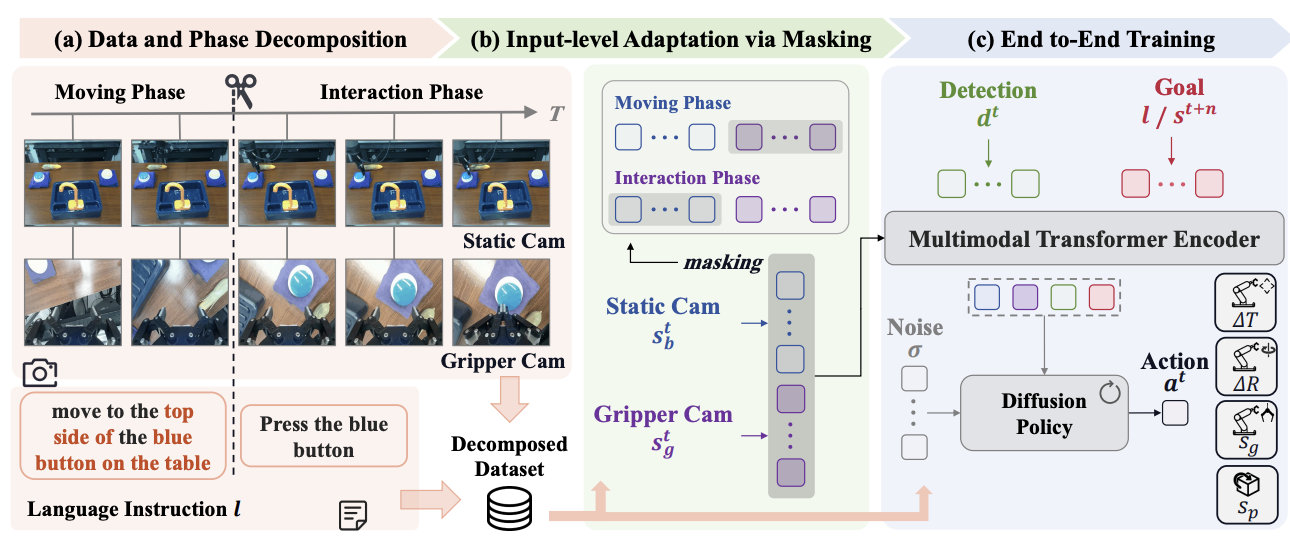
Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
Yiguo Fan, Shuanghao Bai, Xinyang Tong, Pengxiang Ding, Yuyang Zhu, Hongchao Lu, Fengqi Dai, Wei Zhao, Yang Liu, Siteng Huang, Zhaoxin Fan , Badong Chen, Donglin Wang
Conference on Robot Learning (CoRL), 2025.
[Paper] [Code]

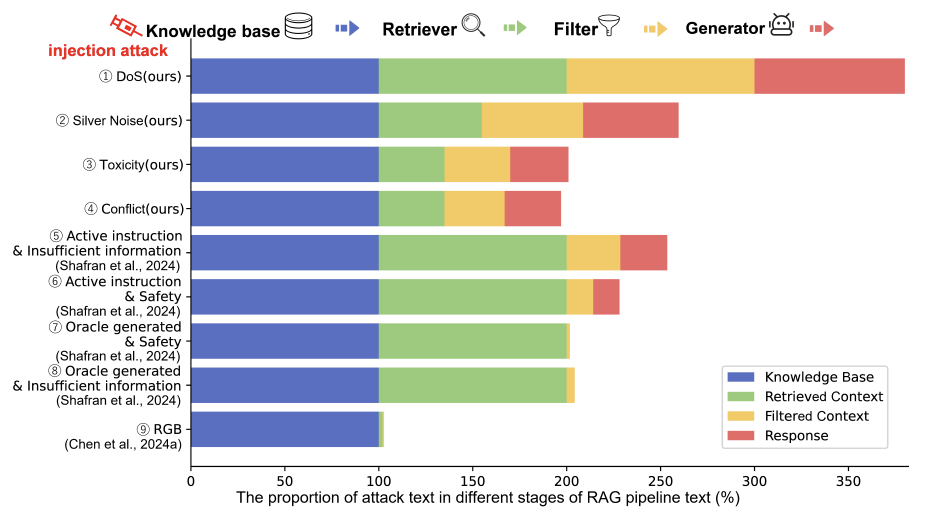
SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
Xun Liang, Simin Niu, Zhiyu Li, Sensen Zhang, Hanyu Wang, Feiyu Xiong, Zhaoxin Fan, Bo Tang, Jihao Zhao, Jiawei Yang, Shichao Song, Mengwei Wang
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025.
[Paper] [Code]

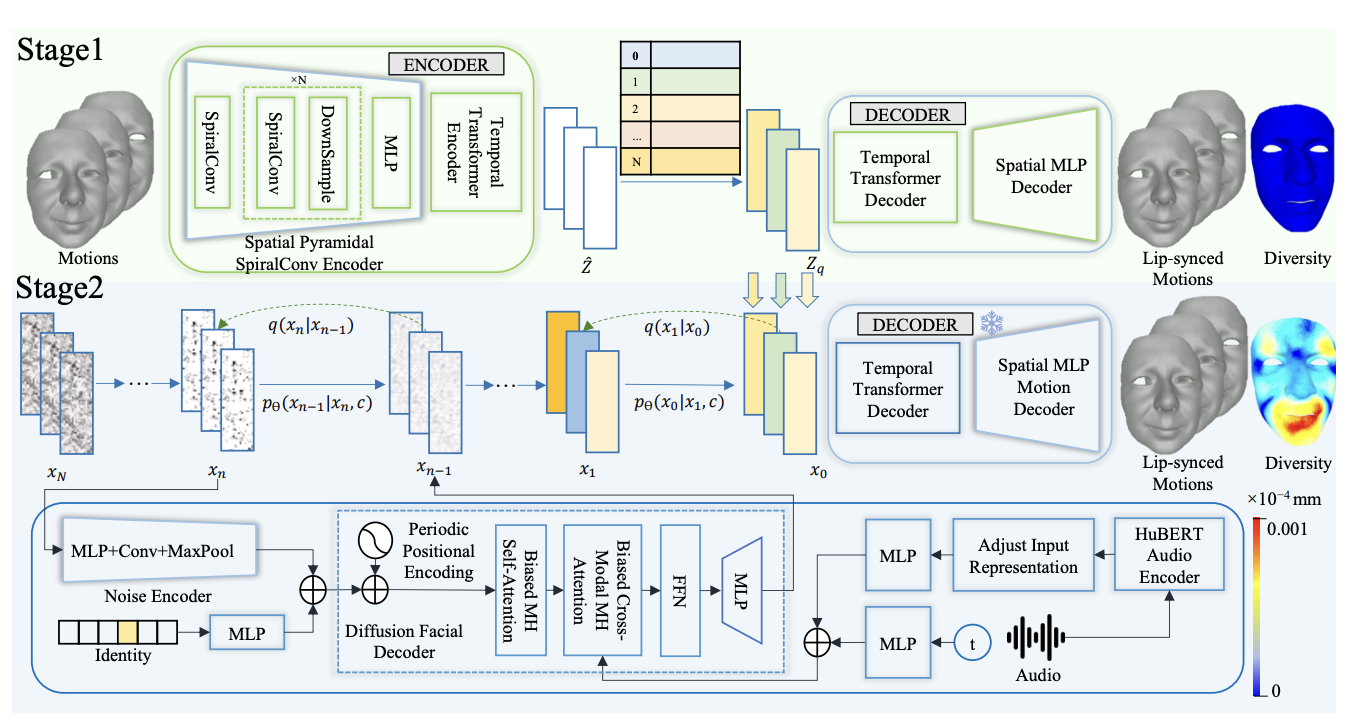
GLDiTalker: Speech-Driven 3D Facial Animation with Graph Latent Diffusion Transformer
Yihong Lin, Zhaoxin Fan (Equal Contribution), Xianjia Wu, Lingyu Xiong, Liang Peng, Xiandong Li, Wenxiong Kang, Songju Lei, Huang Xu
34th International Joint Conference on Artificial Intelligence (IJCAI), 2025.
[Paper] [Code]
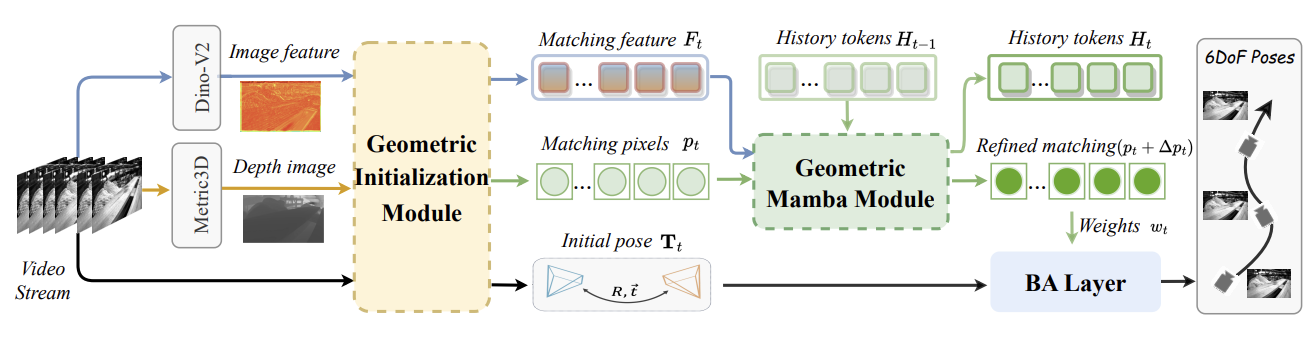
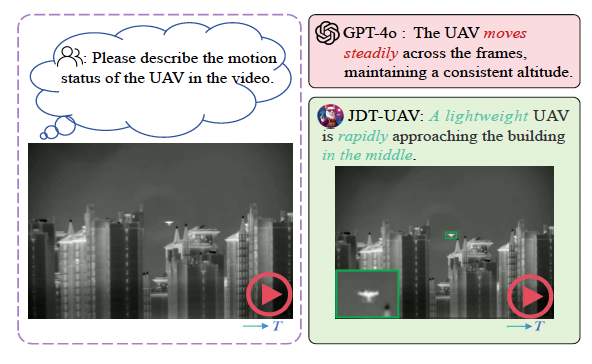
JTD-UAV: MLLM-Enhanced Joint Tracking and Description Framework for Anti-UAV Systems
Yifan Wang, Jian Zhao, Zhaoxin Fan (corresponding author), Xin Zhang, Xuecheng Wu, Yudian Zhang, Lei Jin, Xinyue Li, Gang Wang, Mengxi Jia, Ping Hu, Zheng Zhu, Xuelong Li
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
[Paper] [Code]
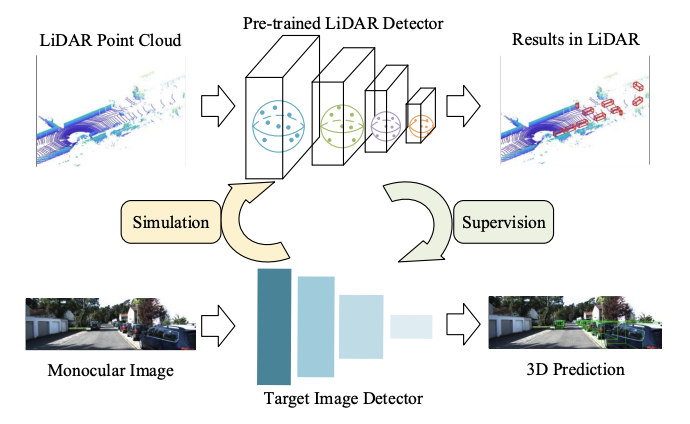
Everything2Motion: Synchronizing Diverse Inputs via a Unified Framework for Human Motion Synthesis
Zhaoxin Fan, Longbin Li, Pengxin Xu, Fan Shen, Kai Chen
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), 2024.
[Paper]
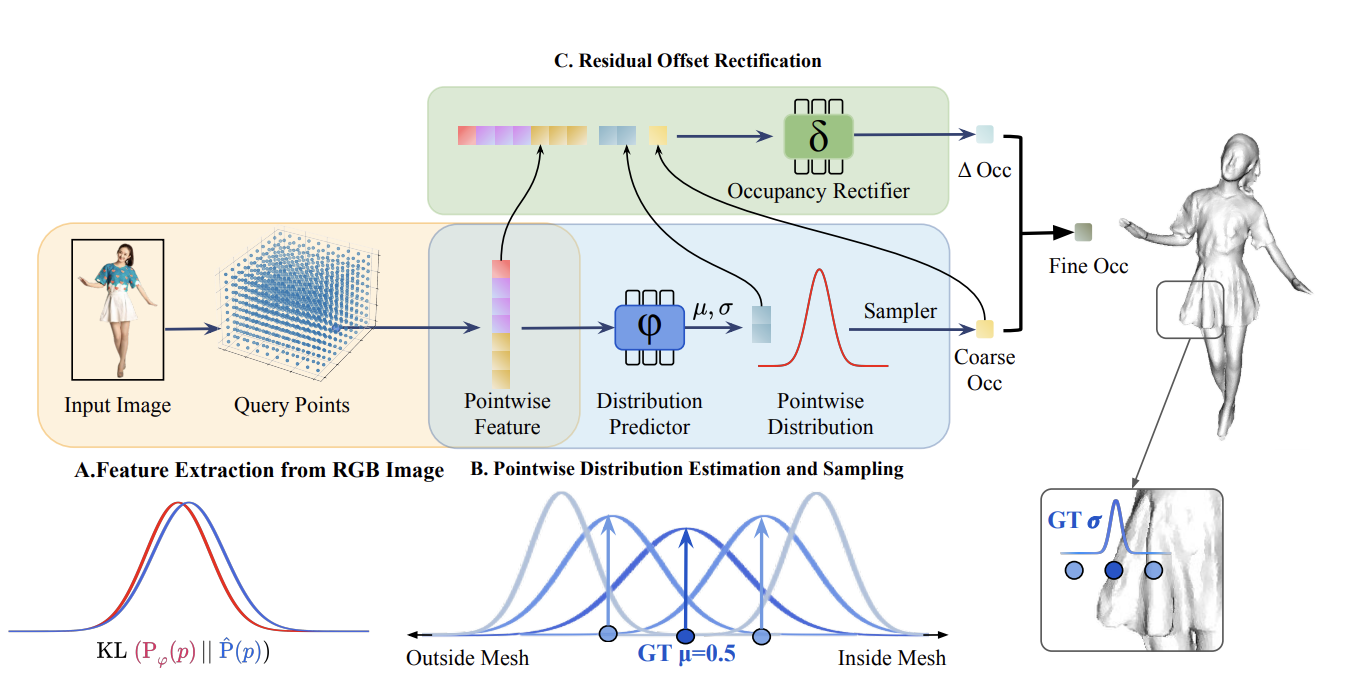
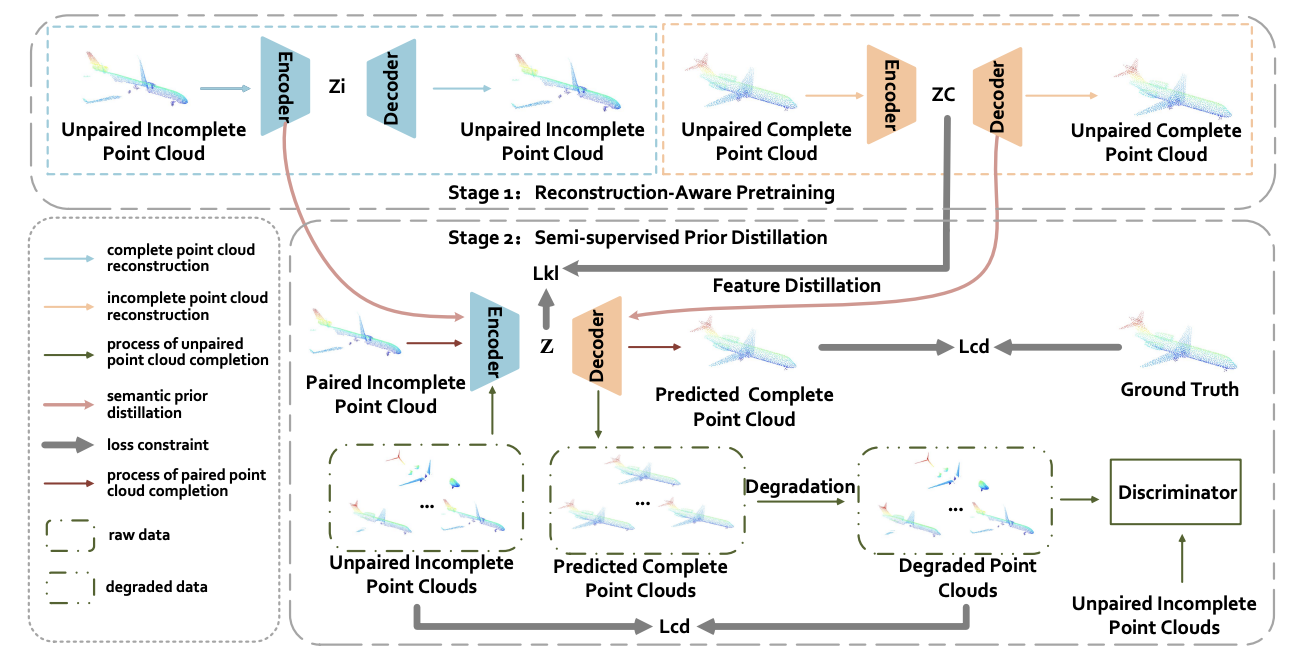
Reconstruction-Aware Prior Distillation for Semi-supervised Point Cloud Completion
Zhaoxin Fan, Yulin He, Zhicheng Wang, Kejian Wu, Hongyan Liu, Jun He
International Joint Conference on Artificial Intelligence (IJCAI), 2023.
[Paper]
Robust Single Image Reflection Removal Against Adversarial Attacks
Zhenbo Song, Zhenyuan Zhang, Kaihao Zhang, Wenhan Luo, Zhaoxin Fan, Wenqi Ren, Jianfeng Lu
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
[Paper]
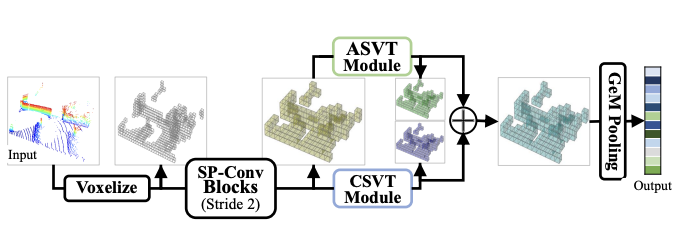
Deep Learning on Monocular Object Pose Detection and Tracking: A Comprehensive Overview
Zhaoxin Fan, Yazhi Zhu, Yulin He, Qi Sun, Hongyan Liu, Jun He
ACM Computing Surveys (CSUR), 2022.
[Paper]
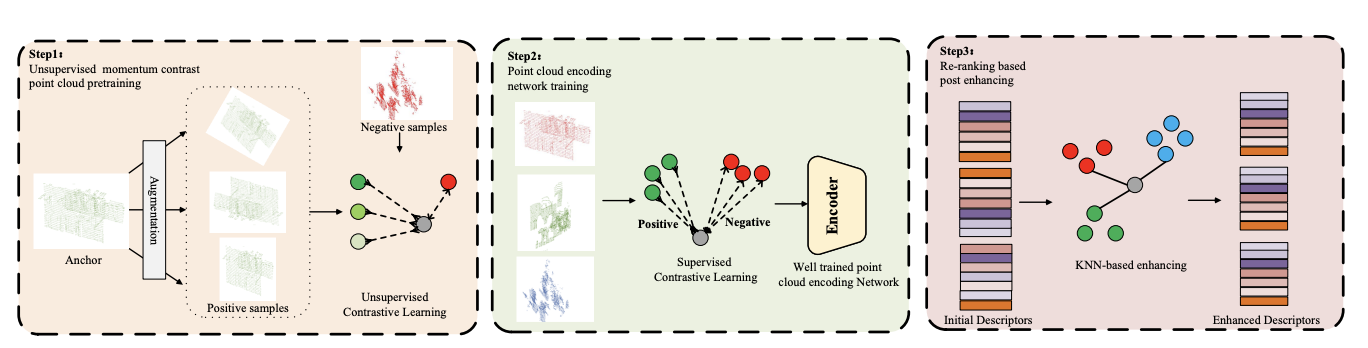
GIDP: Learning a Good Initialization and Inducing Descriptor Post-enhancing for Large-scale Place Recognition
Zhaoxin Fan, Zhenbo Song, Hongyan Liu, Jun He
International Conference on Robotics and Automation (ICRA), 2023.
[Paper]
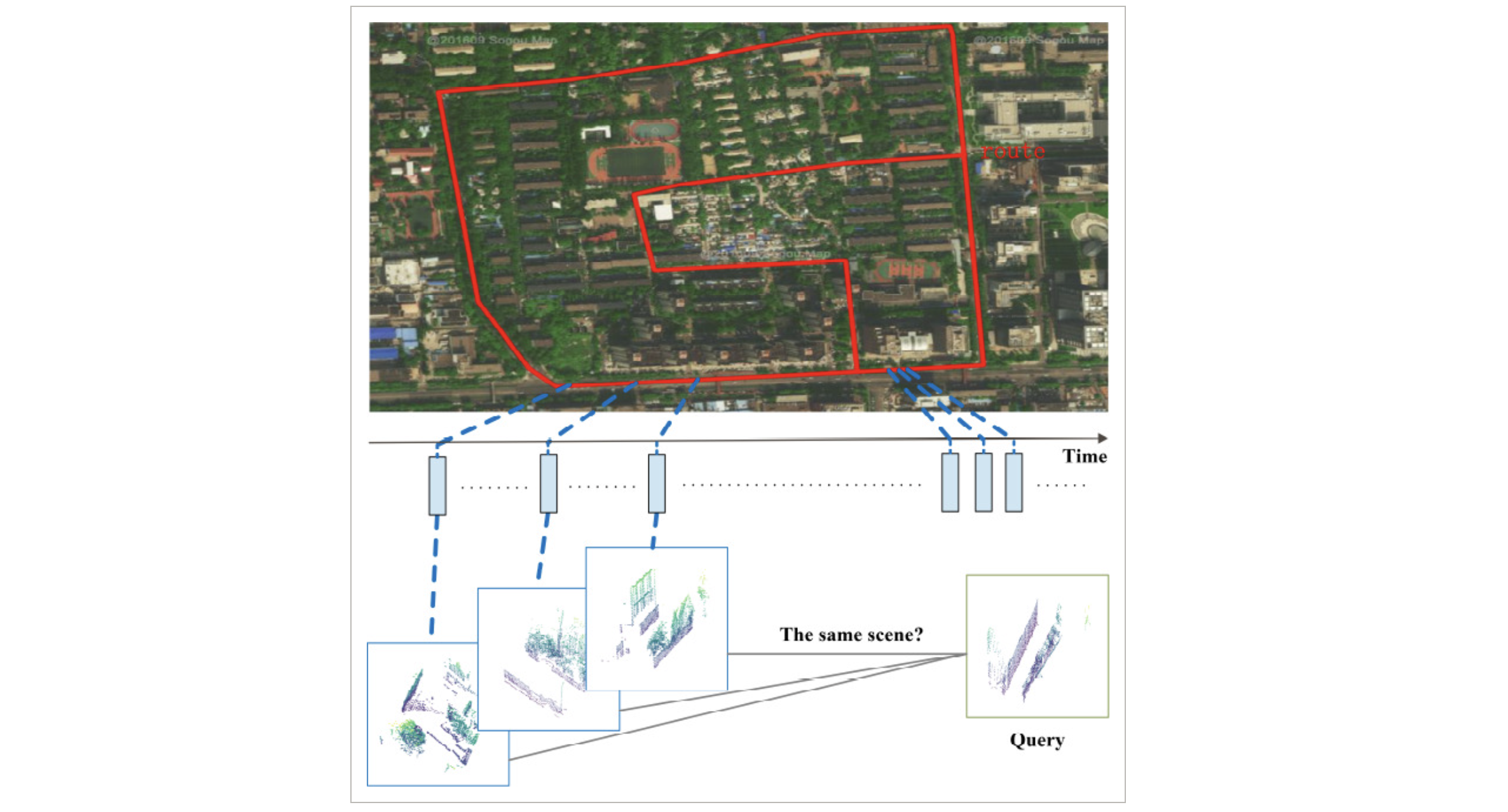
SRNet: A 3D Scene Recognition Network using Static Graph and Dense Semantic Fusion
Zhaoxin Fan, Hongyan Liu, Jun He, Qi Sun, Xiaoyong Du
Computer Graphics Forum (CGF), 2020.
[Paper]
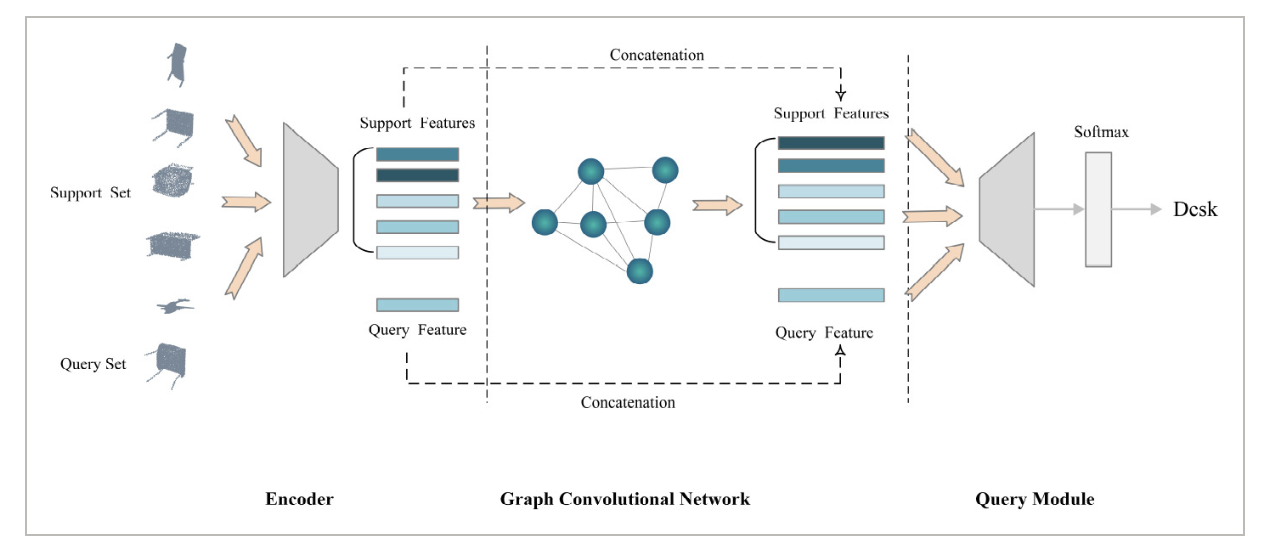
A Graph‐based One‐Shot Learning Method for Point Cloud Recognition
Zhaoxin Fan, Hongyan Liu, Jun He, Qi Sun, Xiaoyong Du
Computer Graphics Forum (CGF), 2020.
[Paper]