
2026
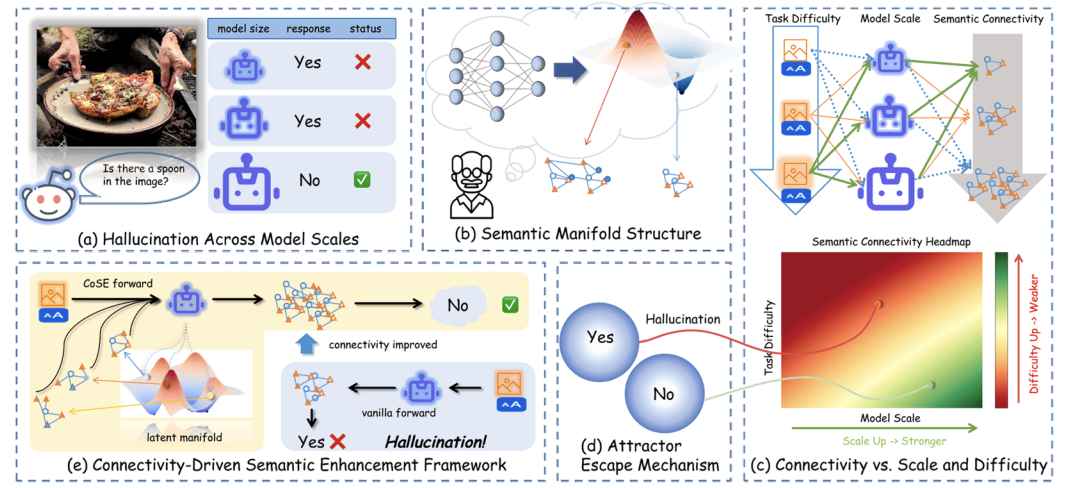

Z-Erase: Enabling Concept Erasure in Single-Stream Diffusion Transformers
Nanxiang Jiang, Zhaoxin Fan (corresponding author), Baisen Wang, Daiheng Gao, Junhang Cheng, Jifeng Guo, Yalan Qin, Yeying Jin, Hongwei Zheng, Faguo Wu, Wenjun Wu
International Conference on Machine Learning (ICML), 2026.
[Paper] [Code]
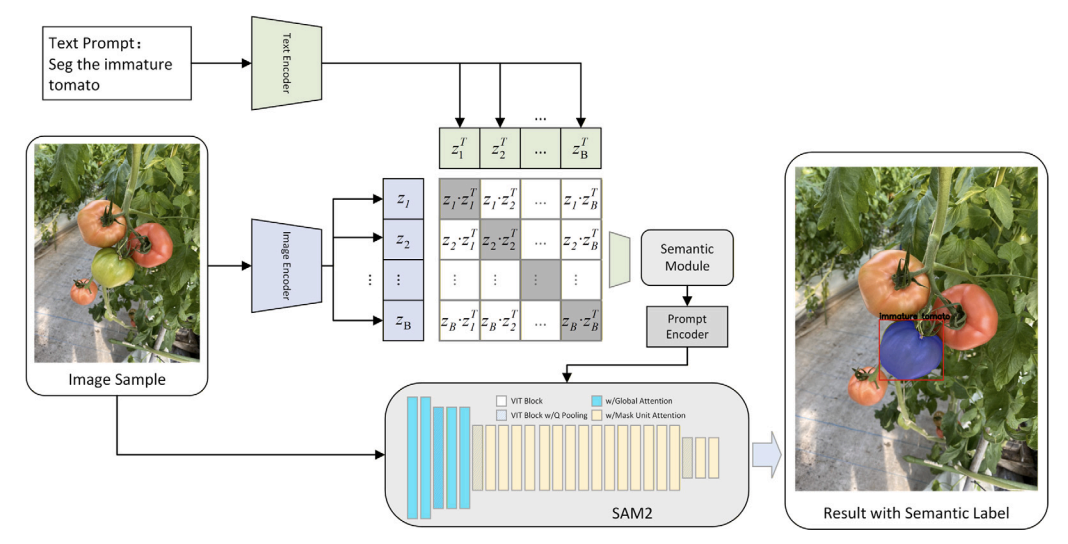
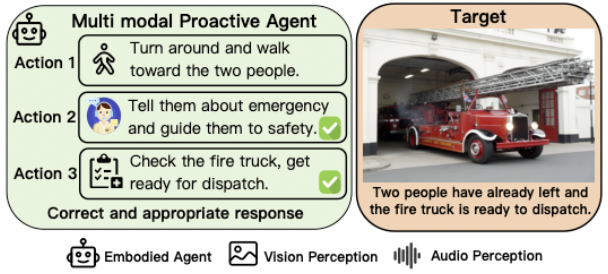
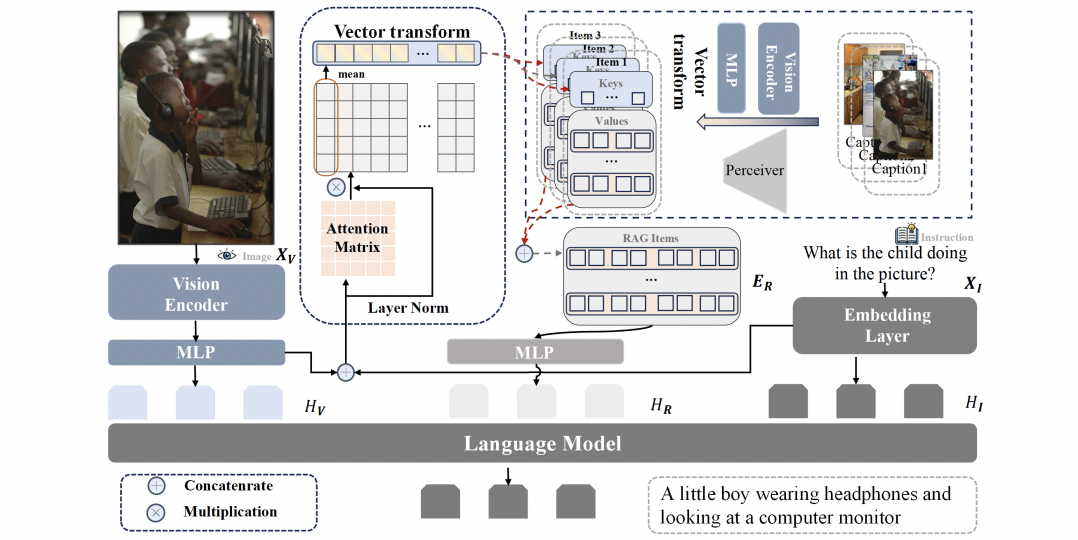
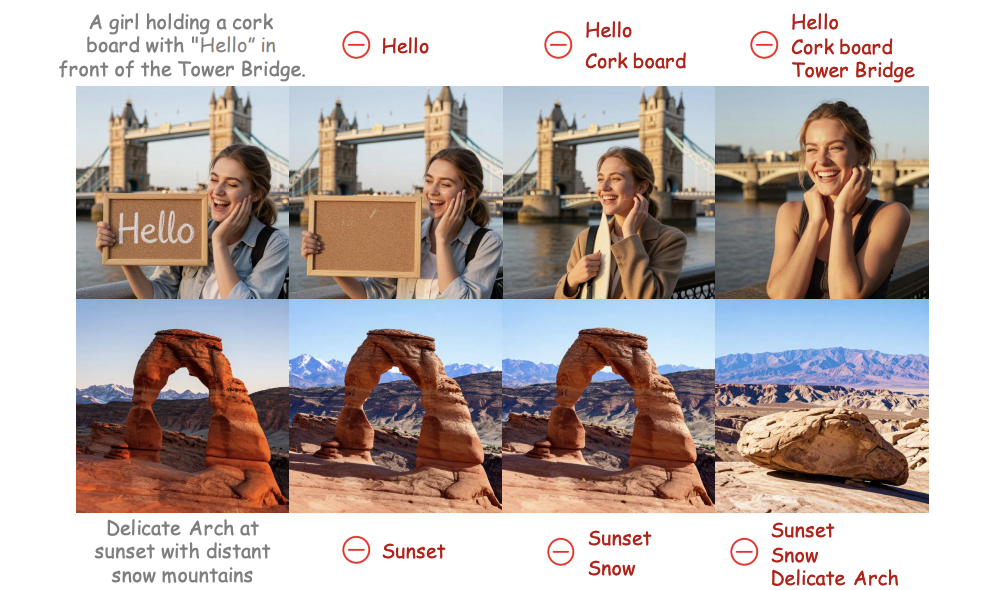
TinyAlign: Boosting Lightweight Vision-Language Models by Mitigating Modal Alignment Bottlenecks
Yuanze Hu, Zhaoxin Fan (corresponding author), Xinyu Wang, Gen Li, Ye Qiu, Zhichao Yang, Wenjun Wu, Kejian Wu, Yifan Sun, Xiaotie Deng, Jin Dong
Annual Meeting of the Association for Computational Linguistics (ACL Findings), 2026.
[Paper] [Code]
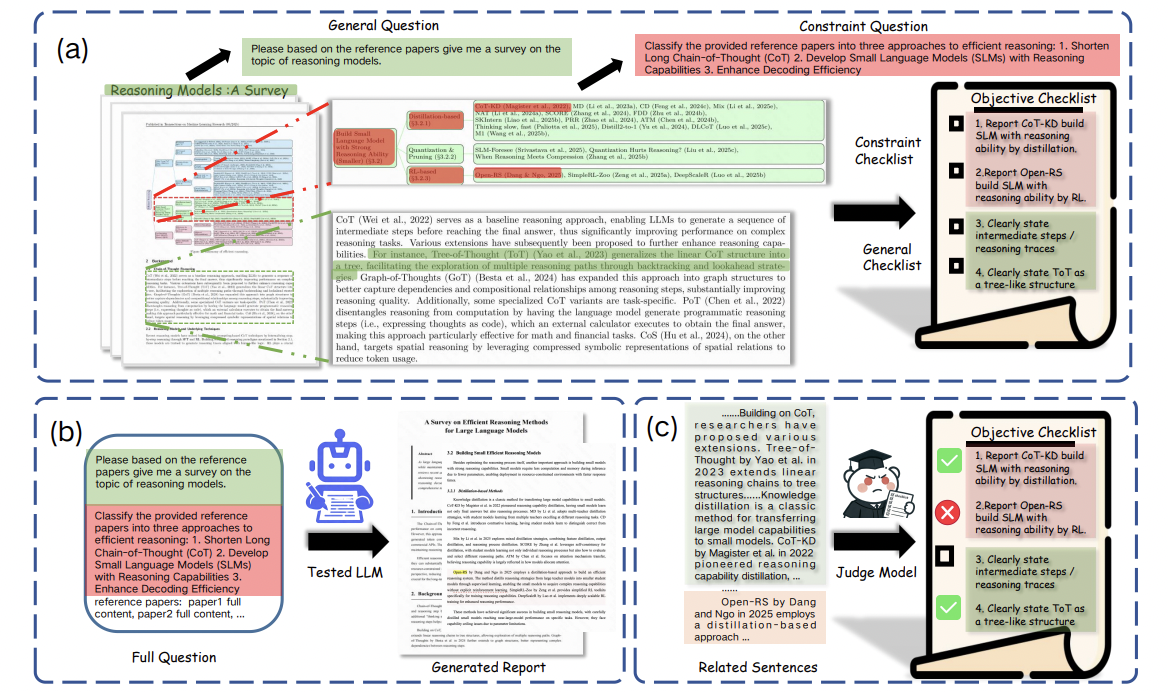
DeepSynth-Eval: Objectively Evaluating Information Consolidation in Deep Survey Writing
Hongzhi Zhang, Yuanze Hu, Tinghai Zhang, Jia Fu, Tao Wang, Junwei Jing, Zhaoxin Fan, Qi Wang, Ruiming Tang, Han Li, Guorui Zhou, Kun Gai
Annual Meeting of the Association for Computational Linguistics (ACL Findings), 2026.
[Paper] [Code]
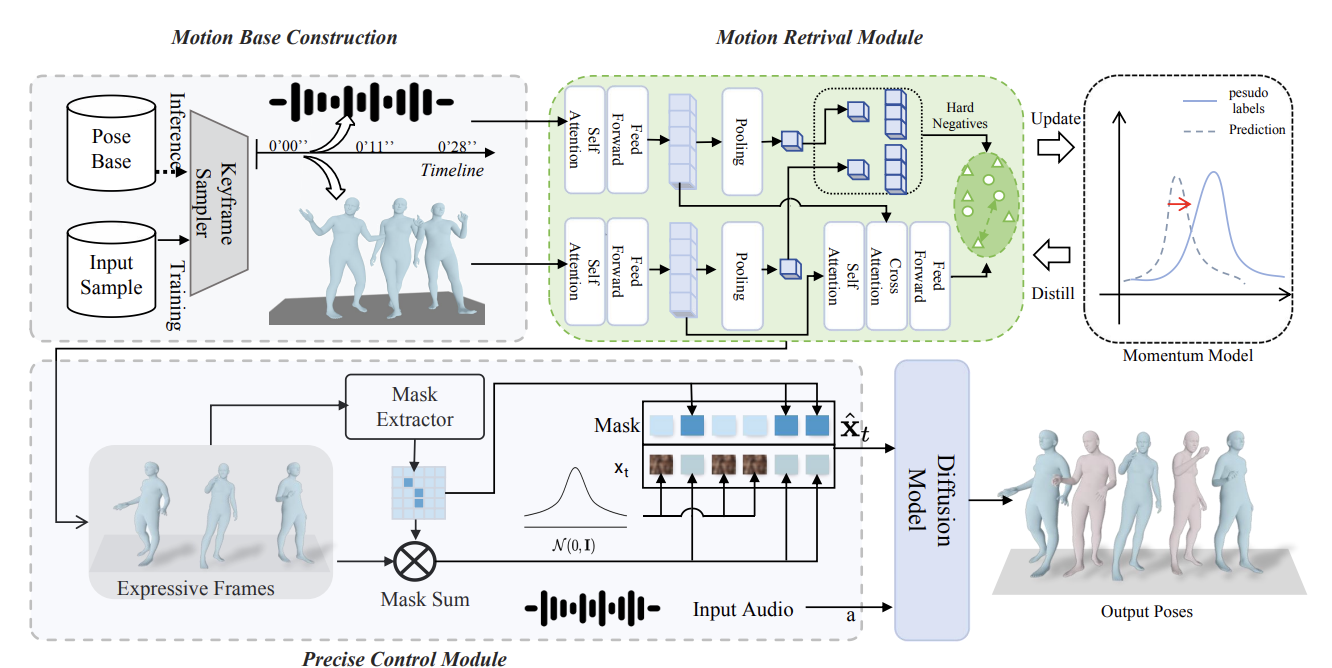
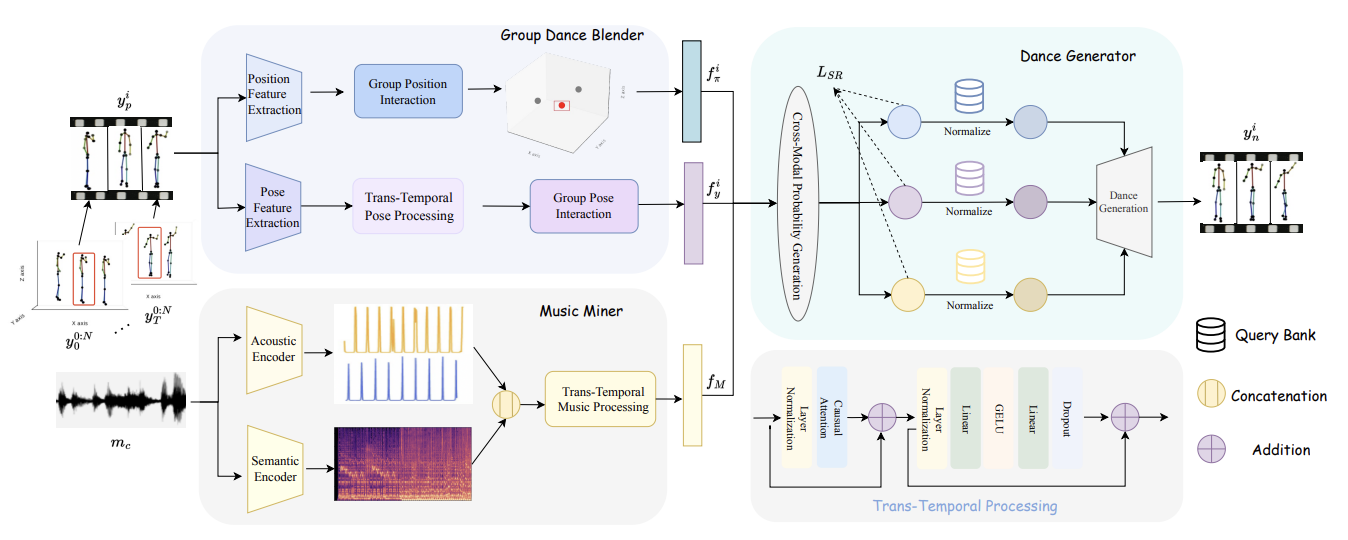
ExGes: Expressive Human Motion Retrieval and Modulation for Audio-Driven Gesture Synthesis
Xukun Zhou, Fengxin Li, Ming Chen, Yan Zhou, Pengfei Wan, Yeying Jin, Hongyuan Zhang, Hongyan Liu, Zhaoxin Fan (corresponding author), Jun He, Xuelong Li
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2026.
[Paper] [Code]
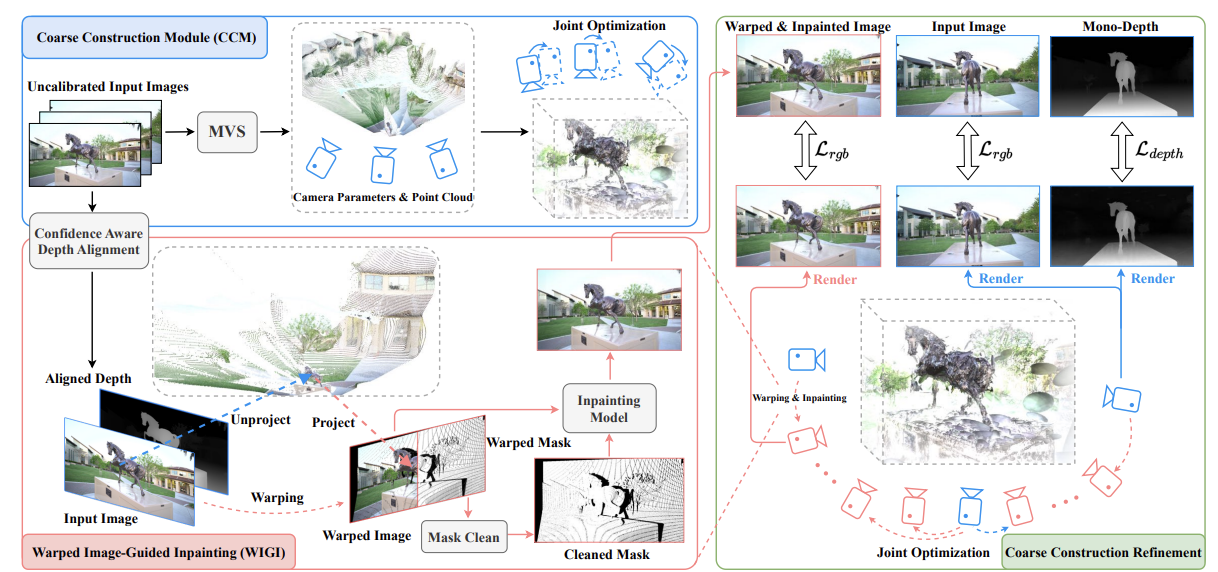
Dust to Tower: Coarse-to-Fine Photo-Realistic Scene Reconstruction from Sparse Uncalibrated Image
Xudong Cai, Yongcai Wang, Zhaoxin Fan (corresponding author), Haoran Deng, Shuo Wang, Wanting Li, Deying Li, Lun Luo, Minhang Wang, Hongyuan Zhang, Xuelong Li
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2026.
[Paper] [Code]

HVG-3D: Bridging Real and Simulation Domains for 3D-Conditional Hand-Object Interaction Video Synthesis
Mingjin Chen, Junhao Chen, Zhaoxin Fan(corresponding author), Yujian Lee, Zichen Dang, Yawen Cui, Lap-Pui Chau, Yi Wang, Lili Wang
Conference on Computer Vision and Pattern Recognition (CVPR), 2026.
[Paper] [Code]
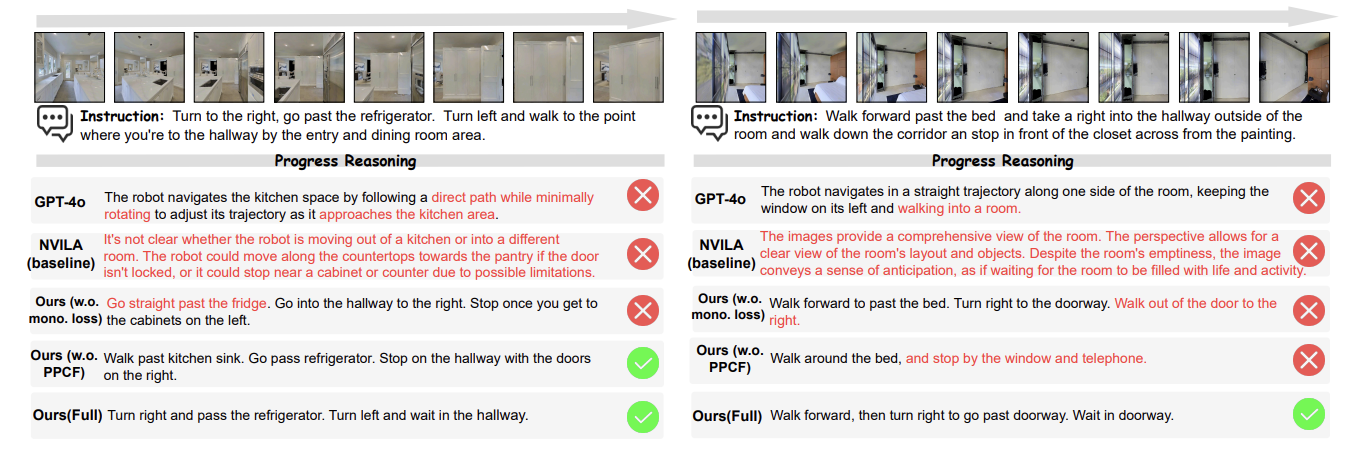
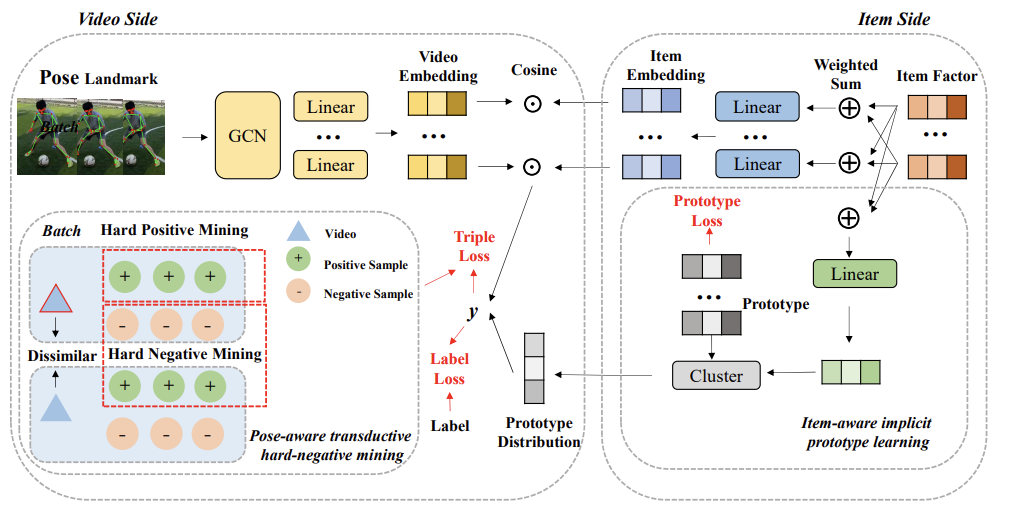
Progress-Think: Semantic Progress Reasoning for Vision-Language Navigation
Shuo Wang, Yucheng Wang, Guoxin Lian, Yongcai Wang, Maiyue Chen, kaihui.wang, Bo Zhang, Zhizhong Su, Zhou Yutian, Wanting Li, Deying Li, Zhaoxin Fan(corresponding author)
Conference on Computer Vision and Pattern Recognition (CVPR), 2026.
[Paper] [Code]
ActAvatar: Temporally-Aware Precise Action Control for Talking Avatars
Ziqiao Peng, Yi Chen, Yifeng Ma, Guozhen Zhang, Zhiyao Sun, Zixiang Zhou, Youliang Zhang, Zhengguang Zhou, Zhaoxin Fan, Hongyan Liu, Yuan Zhou, Qinglin Lu, Jun He
Conference on Computer Vision and Pattern Recognition (CVPR), 2026.
[Paper] [Code]
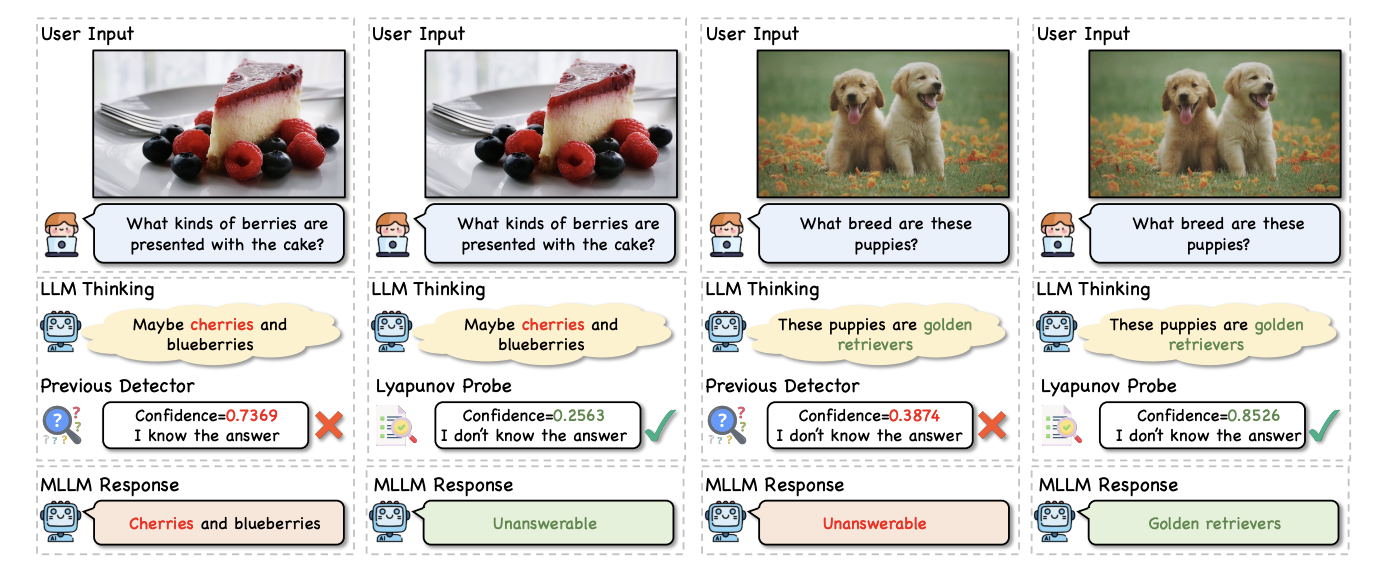

Erased, But Not Forgotten: Erased Rectified Flow Transformers Still Remain Unsafe Under Concept Attack
Nanxiang Jiang, Zhaoxin Fan(corresponding author), Enhan Kang, Daiheng Gao, Yun Zhou, Yanxia Chang, Zheng Zhu, Yeying Jin, Wenjun Wu
Conference on Computer Vision and Pattern Recognition (CVPR (Findings)) , 2026.
[Paper] [Code]
2025
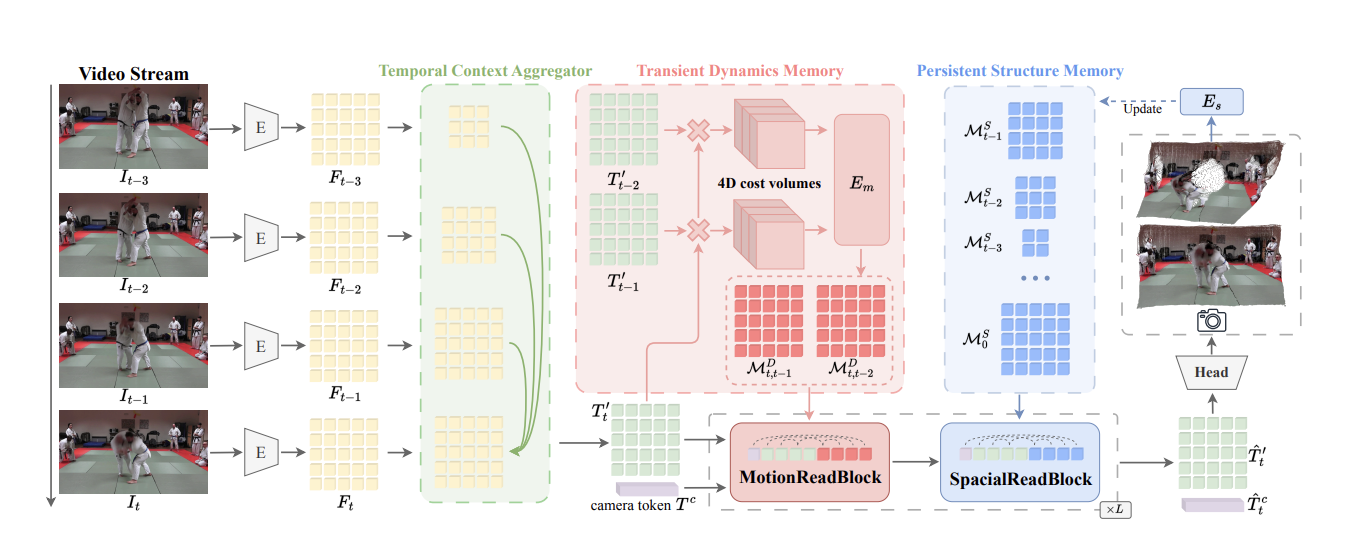

MonoDream: Monocular Vision-Language Navigation with Panoramic Dreaming
Shuo Wang, Yongcai Wang, Wanting Li, Yucheng Wang, Maiyue Chen, Kaihui Wang, Zhizhong Su, Xudong Cai, Yeying Jin, Deying Li, Zhaoxin Fan (corresponding author)
AAAI Conference on Artificial Intelligence (AAAI), 2026.
[Paper] [Code]

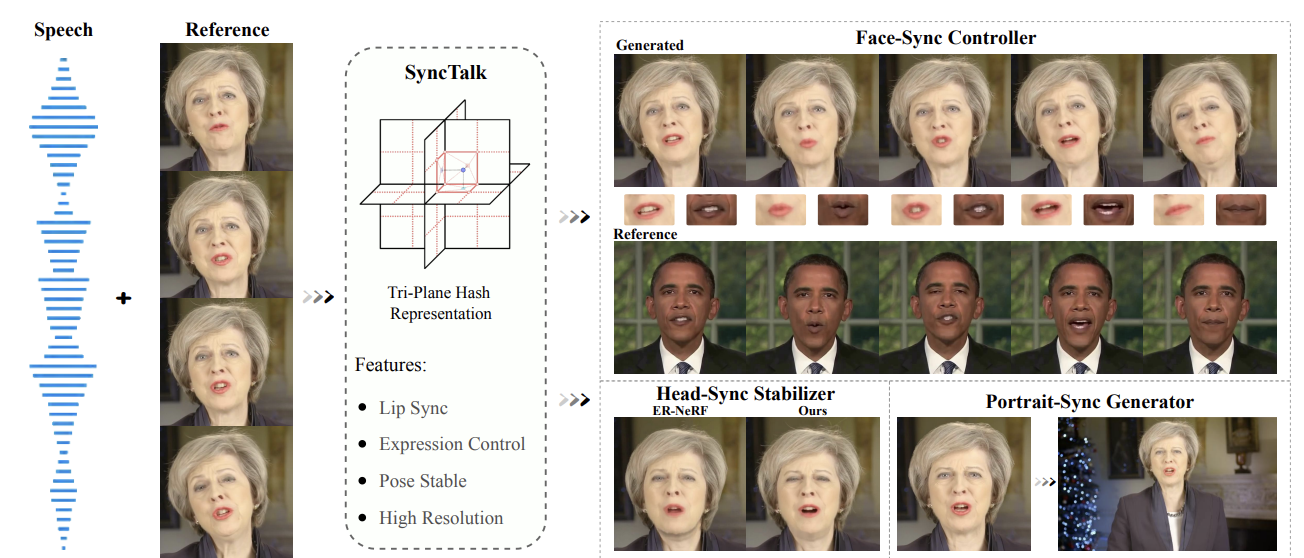
SyncTalk++: High-Fidelity and Efficient Synchronized Talking Heads Synthesis Using Gaussian Splatting
Ziqiao Peng, Wentao Hu, Junyuan Ma, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Hui Tian, Jun He, Hongyan Liu, Zhaoxin Fan (corresponding author)
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025.
[Paper] [Code]

Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation
Shuo Wang, Yongcai Wang, Wanting Li, Xudong Cai, Yucheng Wang, Maiyue Chen, Kaihui Wang, Zhizhong Su, Deying Li,Zhaoxin Fan (corresponding author)
Neural Information Processing Systems Conference (NeurIPS), 2025.
[Paper] [Code]
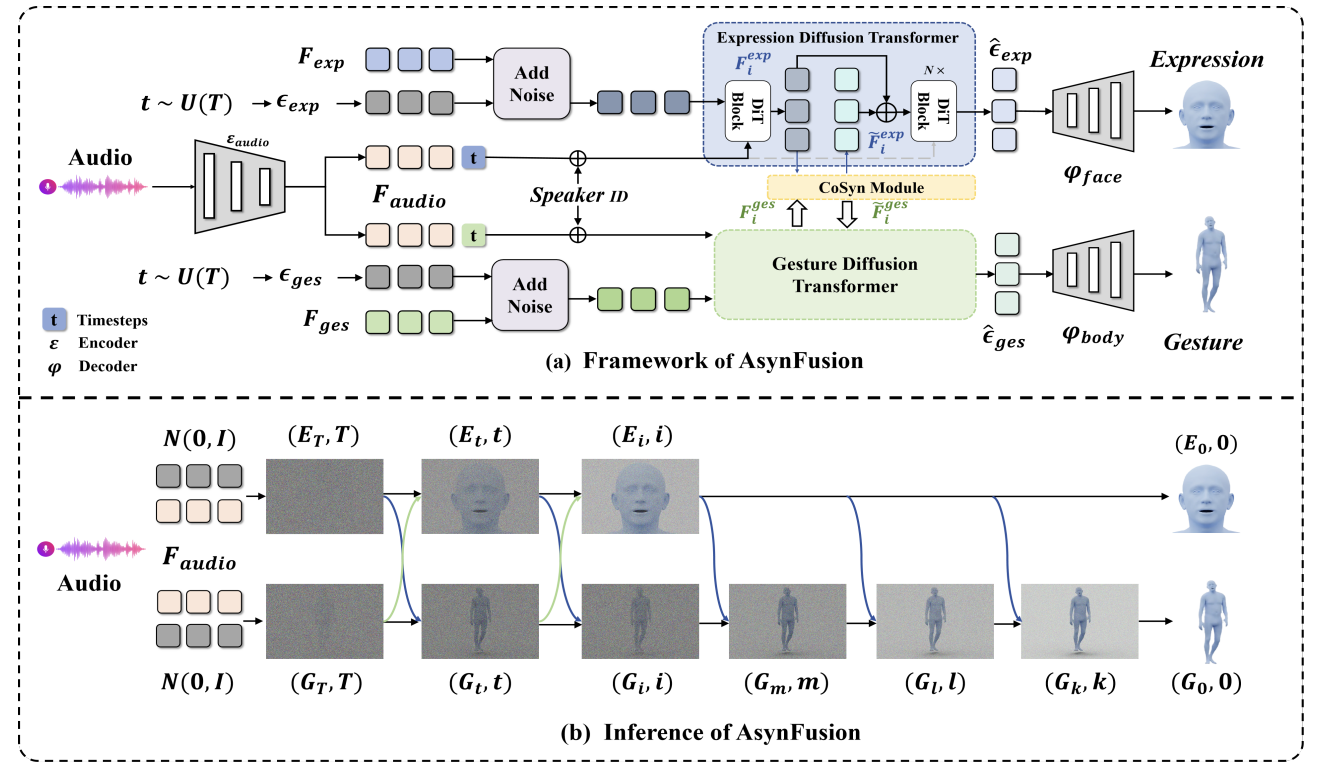
AsynFusion: Towards Asynchronous Latent Consistency Models for Decoupled Whole-Body Audio-Driven Avatars
Tianbao Zhang, Jian Zhao, Yuer Li, Zheng Zhu, Ping Hu, Zhaoxin Fan (corresponding author), Wenjun Wu, Xuelong Li
Chinese Conference on Pattern Recognition and Computer Vision (PRCV Best Student Paper& CCF outstanding Paper), 2025.
[Paper] [Code]
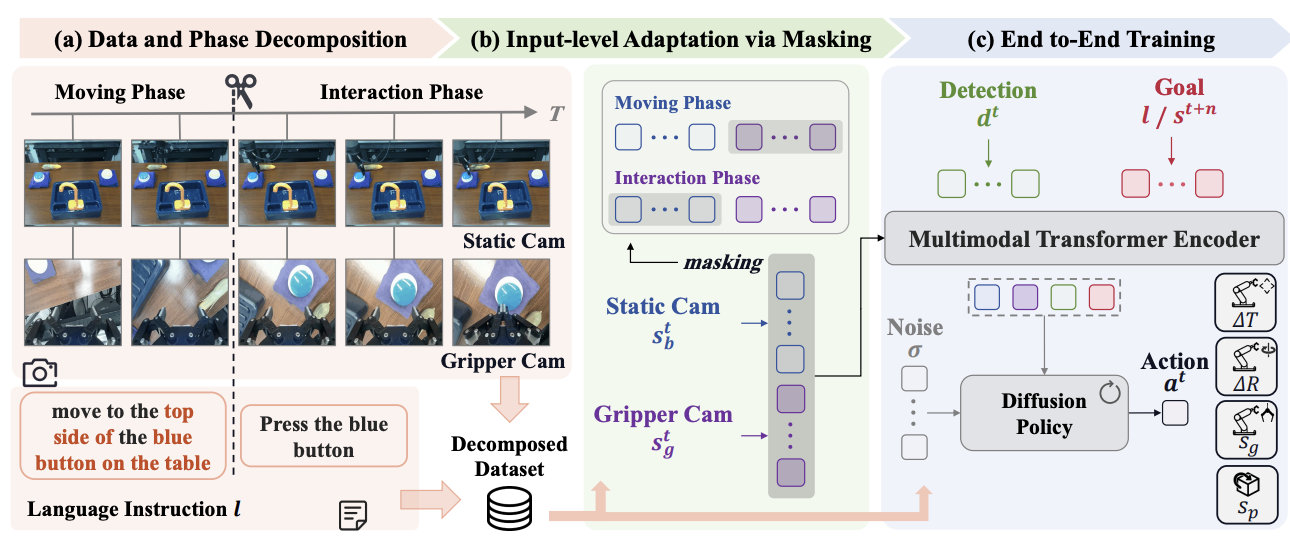
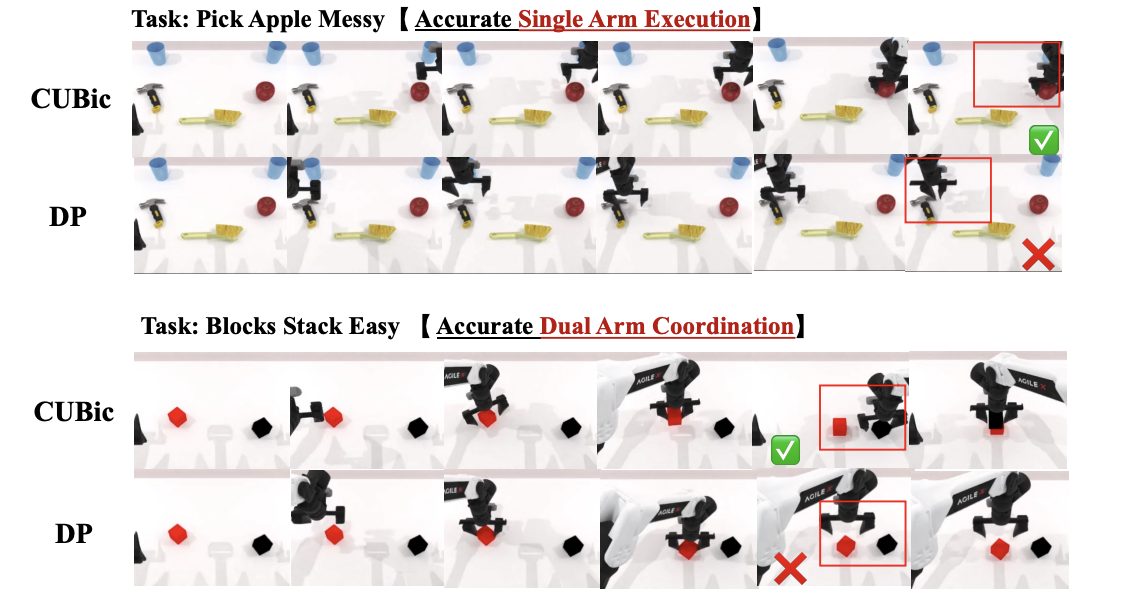
Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
Yiguo Fan, Shuanghao Bai, Xinyang Tong, Pengxiang Ding, Yuyang Zhu, Hongchao Lu, Fengqi Dai, Wei Zhao, Yang Liu, Siteng Huang, Zhaoxin Fan , Badong Chen, Donglin Wang
Conference on Robot Learning (CoRL), 2025.
[Paper] [Code]

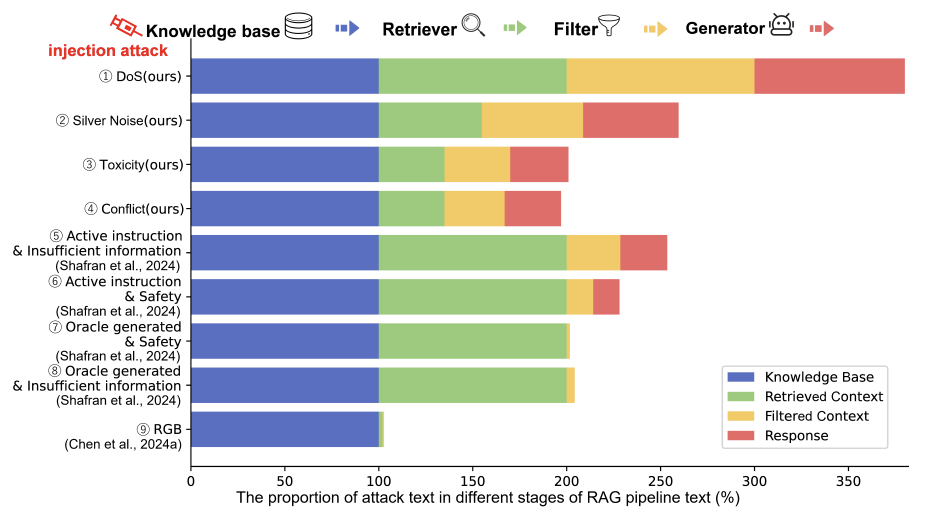
SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
Xun Liang, Simin Niu, Zhiyu Li, Sensen Zhang, Hanyu Wang, Feiyu Xiong, Zhaoxin Fan, Bo Tang, Jihao Zhao, Jiawei Yang, Shichao Song, Mengwei Wang
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025.
[Paper] [Code]
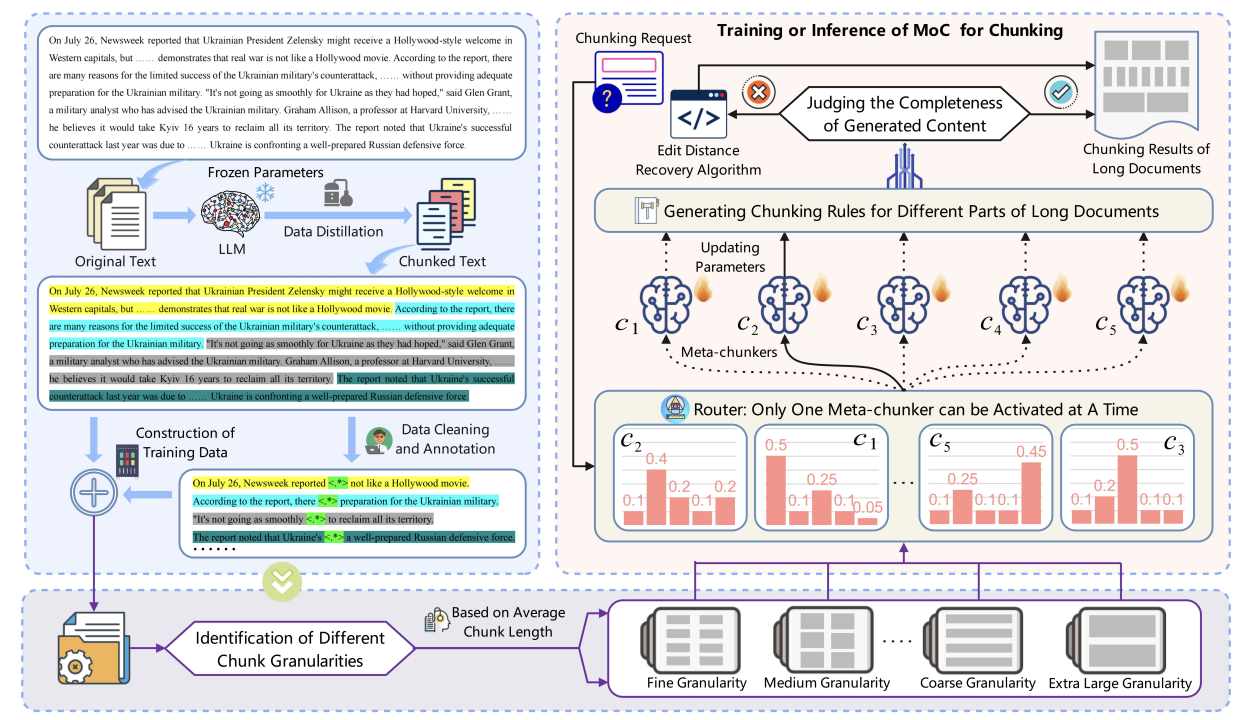

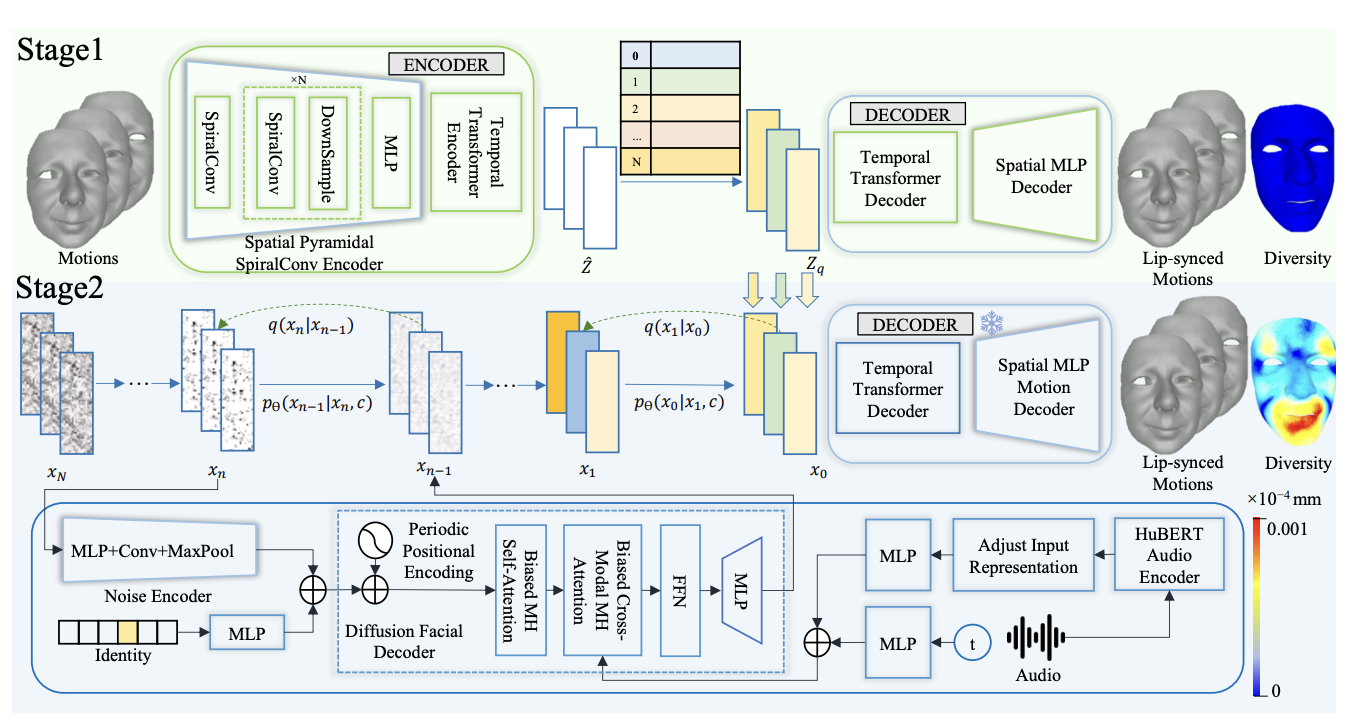
GLDiTalker: Speech-Driven 3D Facial Animation with Graph Latent Diffusion Transformer
Yihong Lin, Zhaoxin Fan (Equal Contribution), Xianjia Wu, Lingyu Xiong, Liang Peng, Xiandong Li, Wenxiong Kang, Songju Lei, Huang Xu
34th International Joint Conference on Artificial Intelligence (IJCAI), 2025.
[Paper] [Code]
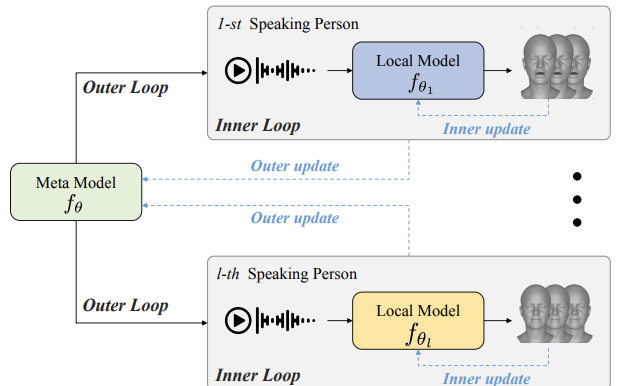
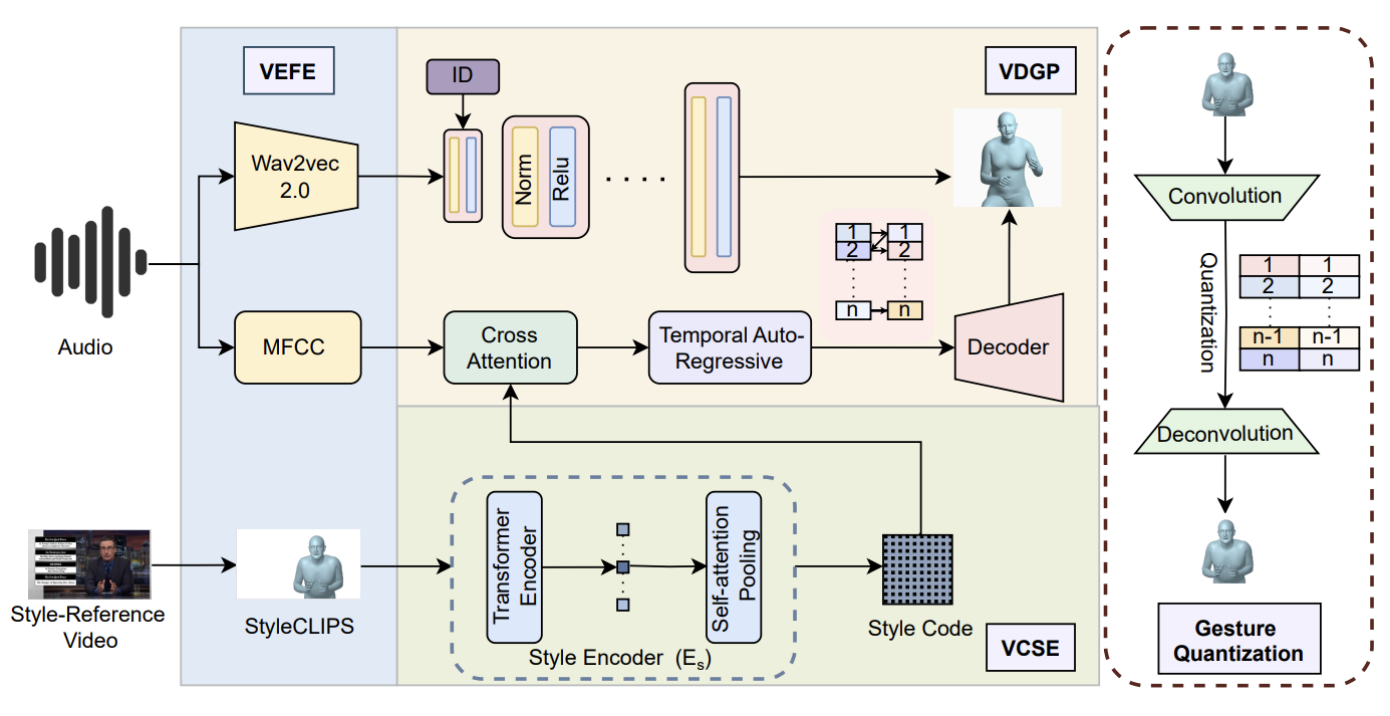
Meta-Learning Empowered Meta-Face: Personalized Speaking Style Adaptation for Audio-Driven 3D Talking Face Animation
Xukun Zhou, Fengxin Li, Ziqiao Peng, Xinyu Wang, Hongyan Liu, Zhaoxin Fan (corresponding author), Jun He
IEEE International Conference on Multimedia and Expo (ICME), 2025.
[Paper] [Code]
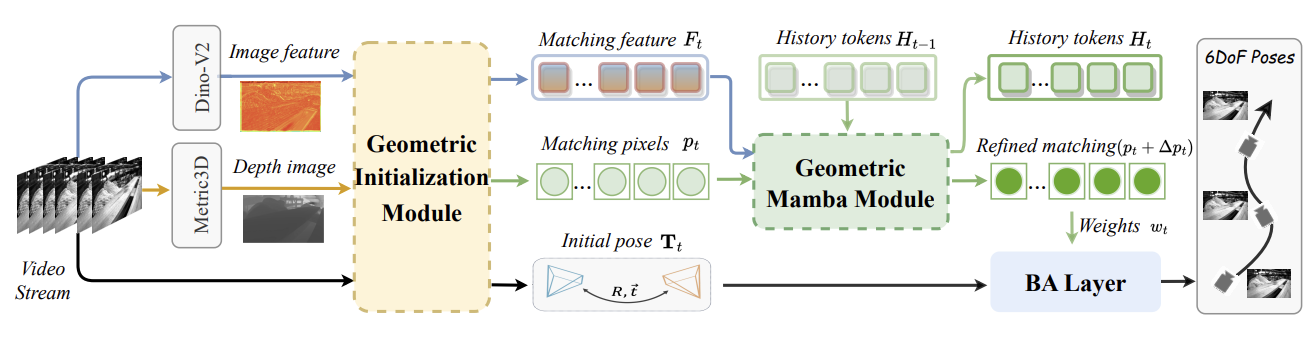
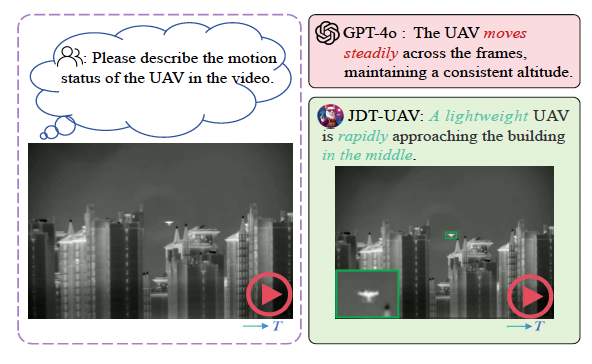
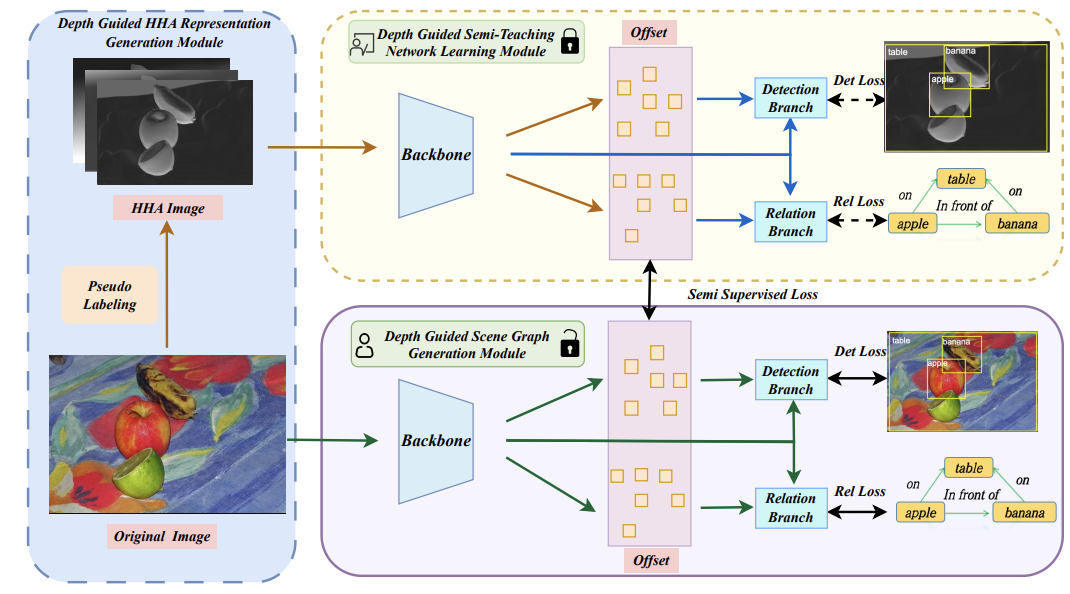
JTD-UAV: MLLM-Enhanced Joint Tracking and Description Framework for Anti-UAV Systems
Yifan Wang, Jian Zhao, Zhaoxin Fan (corresponding author), Xin Zhang, Xuecheng Wu, Yudian Zhang, Lei Jin, Xinyue Li, Gang Wang, Mengxi Jia, Ping Hu, Zheng Zhu, Xuelong Li
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
[Paper] [Code]
2024
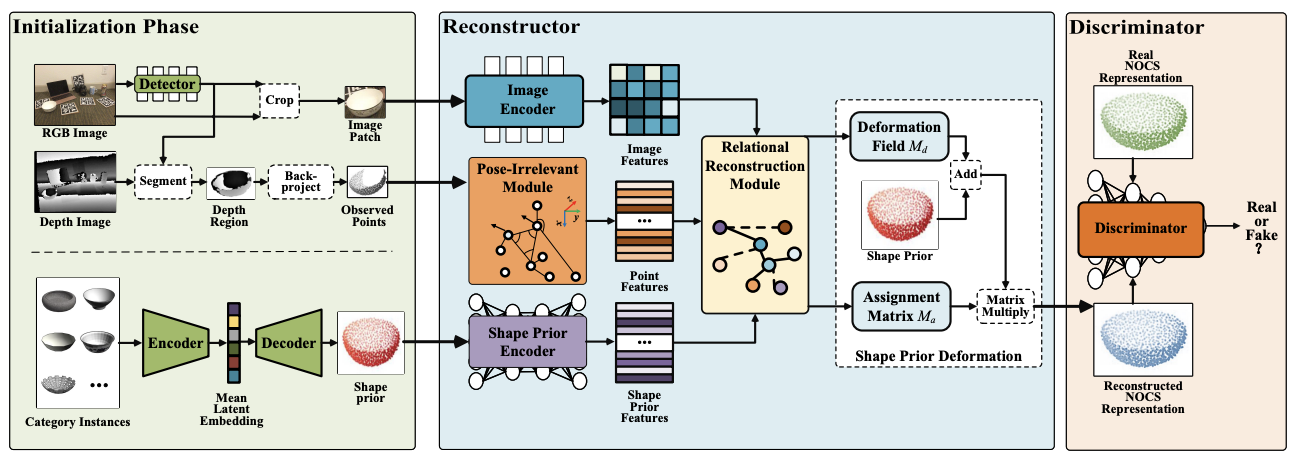
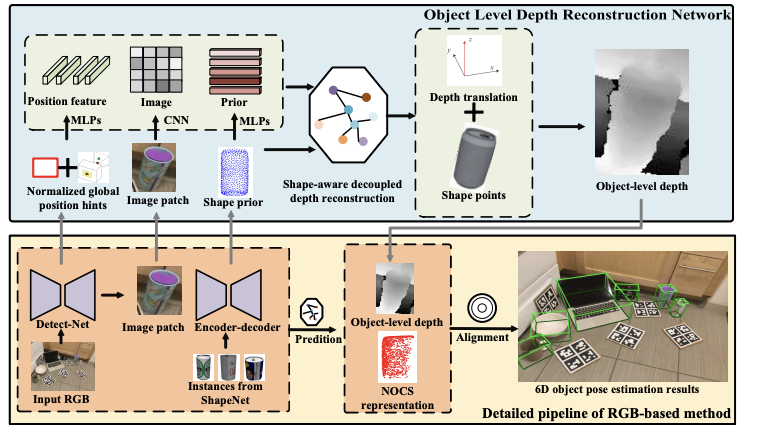
ACR-Pose: Adversarial Canonical Representation Reconstruction Network for Category Level 6D Object Pose Estimation
Zhaoxin Fan, Zhenbo Song, Jian Xu, Zhicheng Wang, Kejian Wu, Hongyan Liu, and Jun He
ACM International Conference on Multimedia Retrieval (ICMR), 2024.
[Paper]
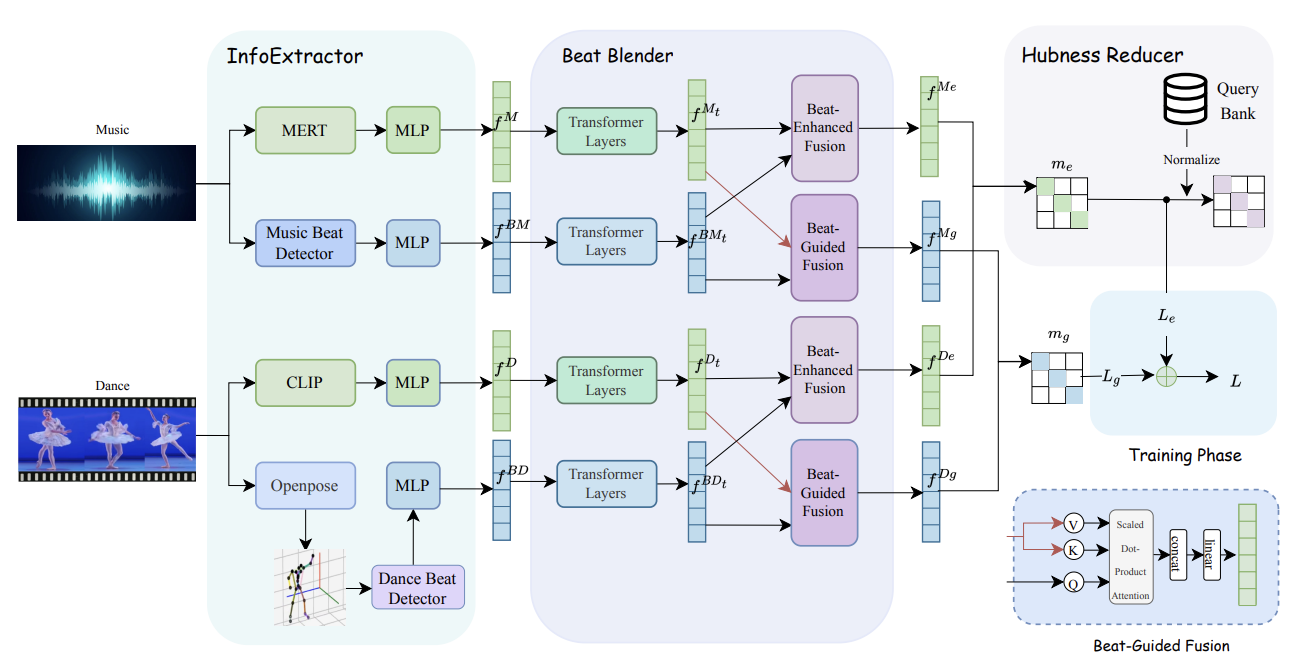
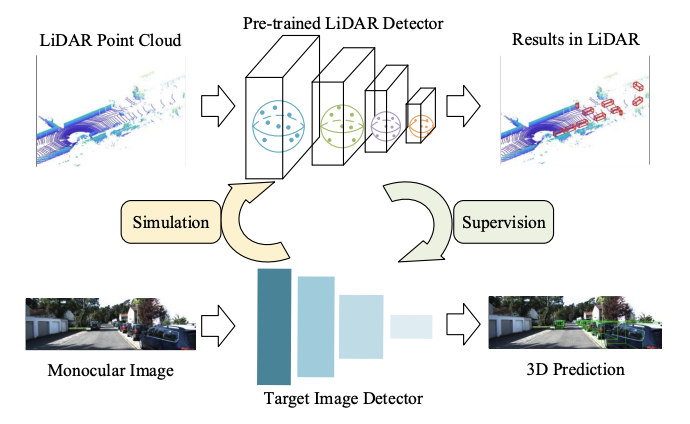
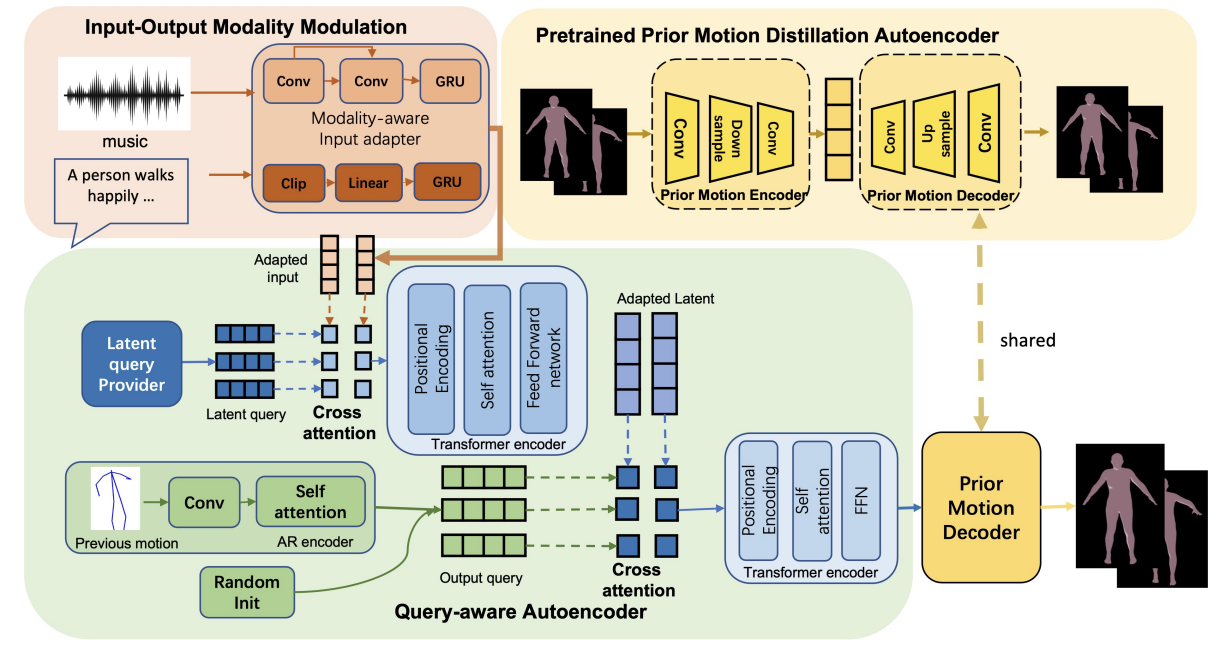
Everything2Motion: Synchronizing Diverse Inputs via a Unified Framework for Human Motion Synthesis
Zhaoxin Fan, Longbin Li, Pengxin Xu, Fan Shen, Kai Chen
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), 2024.
[Paper]
Multi-dimensional Fusion and Consistency for Semi-supervised Medical Image Segmentation
Yixing Lu, Zhaoxin Fan (equal contribution), Min Xu
International Conference on Multimedia Modeling (MMM), 2024.
[Paper]
A Novel Transformer Autoencoder for Multi-modal Emotion Recognition with Incomplete Data
Cheng Cheng, Wenzhe Liu, Zhaoxin Fan, Lin Feng, Ziyu Jia
Neural Networks, 2024.
[Paper]
2023
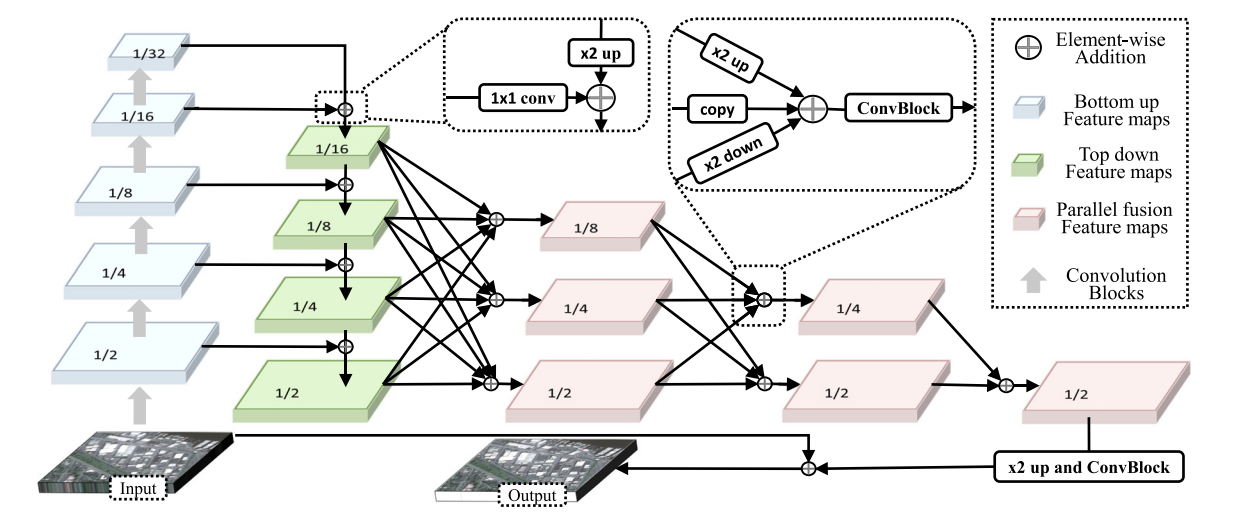
Deep Semantic-aware Remote Sensing Image Deblurring
Zhenbo Song, Zhenyuan Zhang, Feiyi Fang, Zhaoxin Fan, Jianfeng Lu
Signal Processing, 2023.
[Paper]
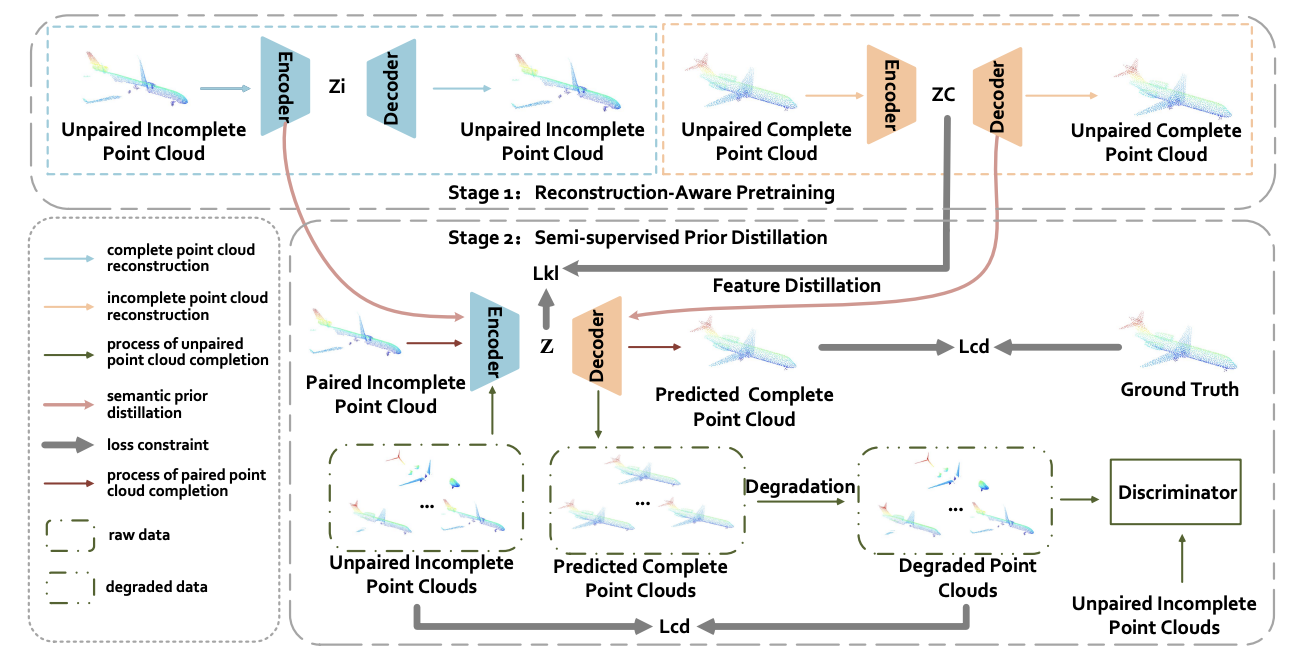
Reconstruction-Aware Prior Distillation for Semi-supervised Point Cloud Completion
Zhaoxin Fan, Yulin He, Zhicheng Wang, Kejian Wu, Hongyan Liu, Jun He
International Joint Conference on Artificial Intelligence (IJCAI), 2023.
[Paper]
Robust Single Image Reflection Removal Against Adversarial Attacks
Zhenbo Song, Zhenyuan Zhang, Kaihao Zhang, Wenhan Luo, Zhaoxin Fan, Wenqi Ren, Jianfeng Lu
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
[Paper]
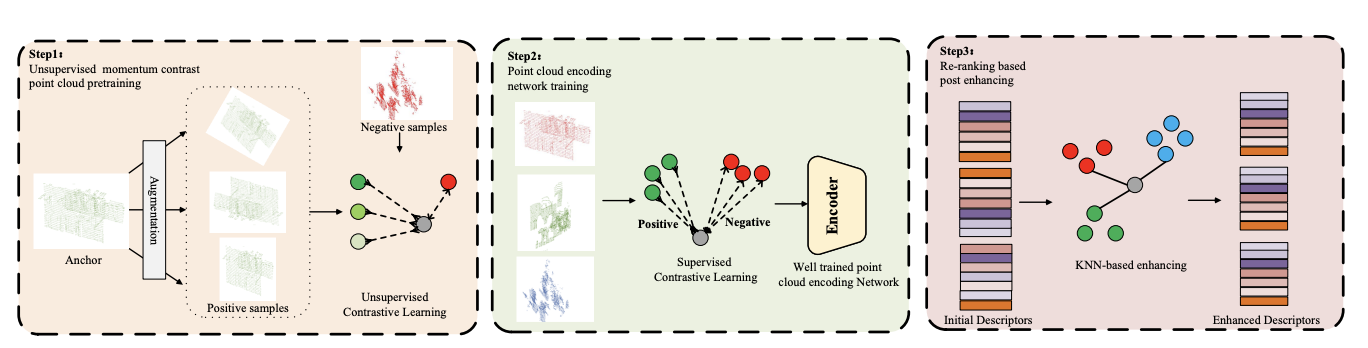
GIDP: Learning a Good Initialization and Inducing Descriptor Post-enhancing for Large-scale Place Recognition
Zhaoxin Fan, Zhenbo Song, Hongyan Liu, Jun He
International Conference on Robotics and Automation (ICRA), 2023.
[Paper]
2022
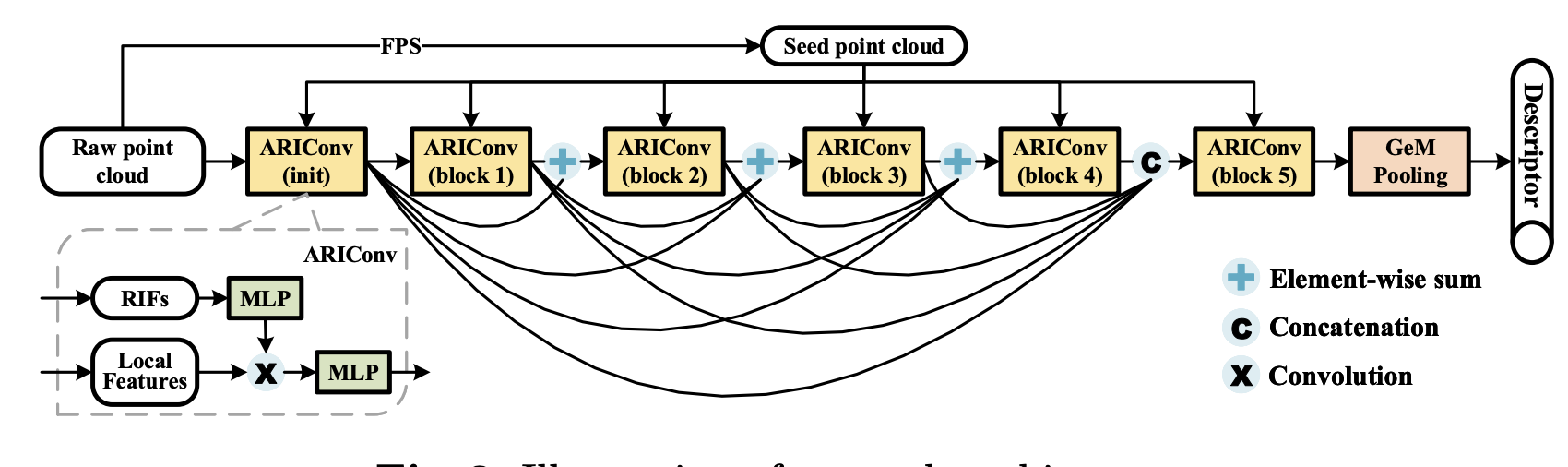
RPR-Net: A Point Cloud-based Rotation-Aware Large Scale Place Recognition Network
Zhaoxin Fan, Zhenbo Song, Wenping Zhang, Hongyan Liu, Jun He, Xiaoyong Du
European Conference on Computer Vision Workshop (ECCV Workshop), 2022.
[Paper]
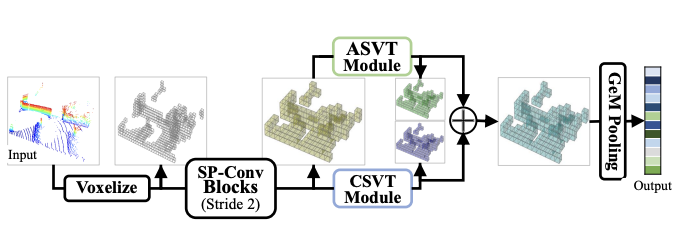
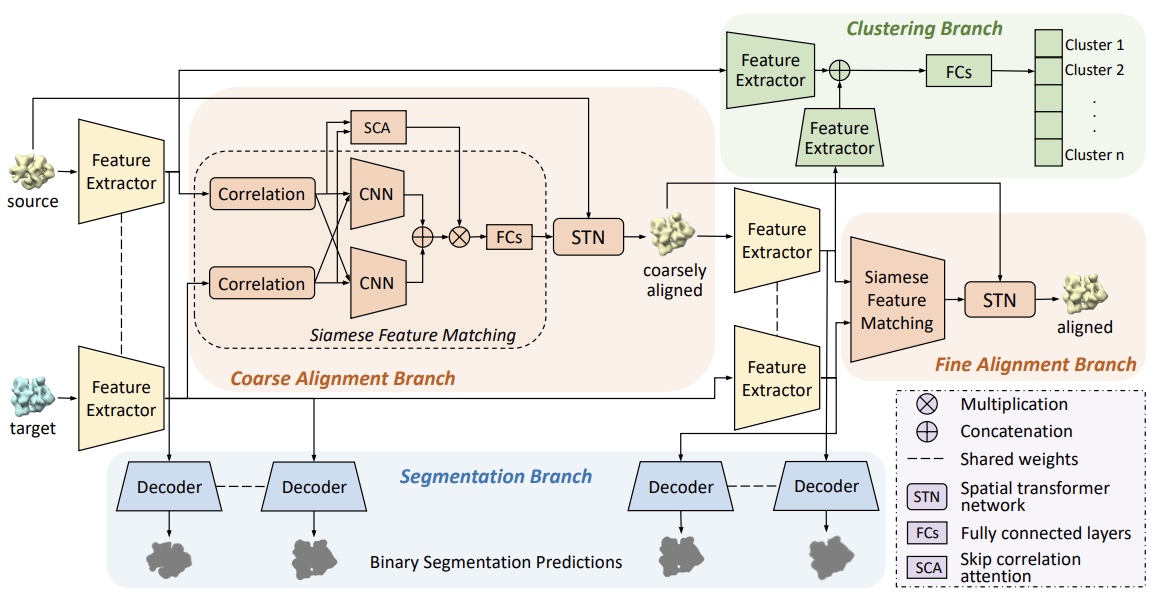
Unsupervised Multi-task Learning for 3D Subtomogram Image Alignment, Clustering and Segmentation
Haoyi Zhu, Chuting Wang, Yuanxin Wang, Zhaoxin Fan, Mostofa Rafid Uddin, Xin Gao, Jing Zhang, Xiangrui Zeng, Min Xu
IEEE International Conference on Information Processing (ICIP), 2022.
[Paper]
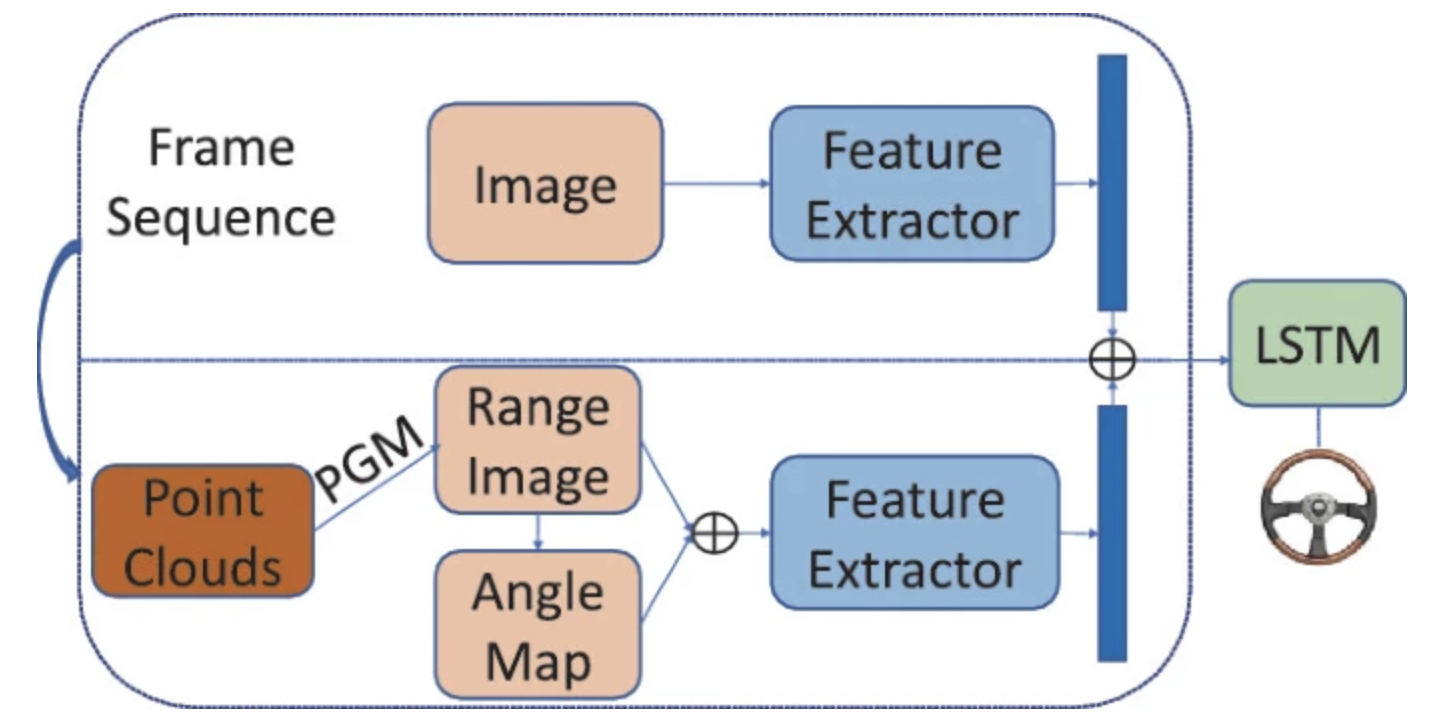
PilotAttnNet: Multi-Modal Attention Network for End-to-End Steering Control
Jincan Zhang, Zhenbo Song, Jianfeng Lu, Xingwei Qu, Zhaoxin Fan
Chinese Conference on Pattern Recognition and Computer Vision (PRCV), 2022.
[Paper]
Deep Learning on Monocular Object Pose Detection and Tracking: A Comprehensive Overview
Zhaoxin Fan, Yazhi Zhu, Yulin He, Qi Sun, Hongyan Liu, Jun He
ACM Computing Surveys (CSUR), 2022.
[Paper]
2020-2021

SRNet: A 3D Scene Recognition Network using Static Graph and Dense Semantic Fusion
Zhaoxin Fan, Hongyan Liu, Jun He, Qi Sun, Xiaoyong Du
Computer Graphics Forum (CGF), 2020.
[Paper]
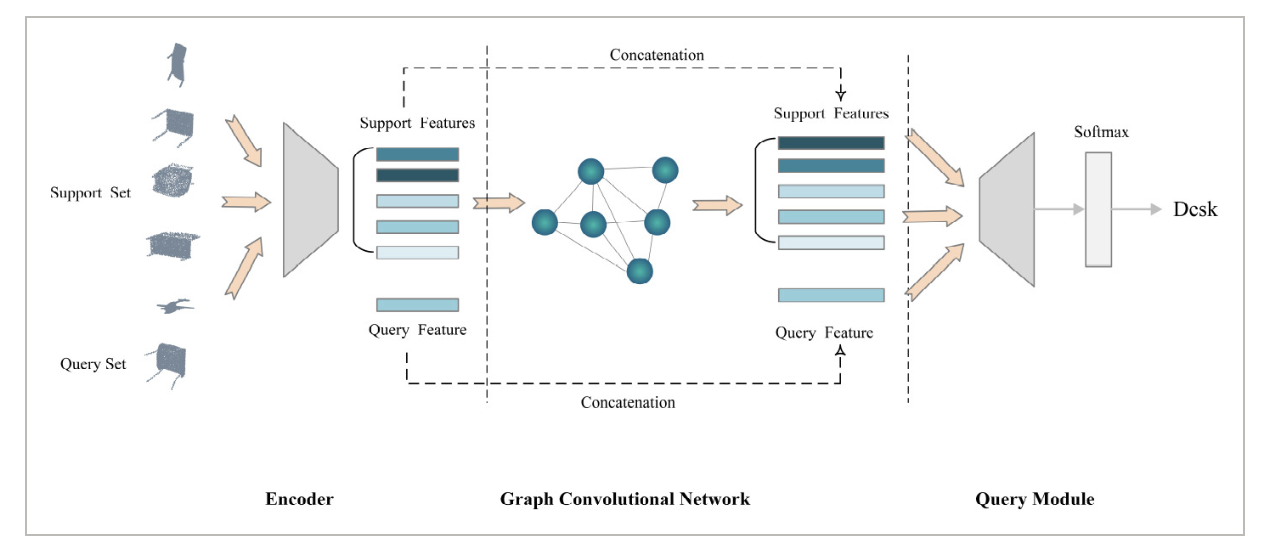
A Graph‐based One‐Shot Learning Method for Point Cloud Recognition
Zhaoxin Fan, Hongyan Liu, Jun He, Qi Sun, Xiaoyong Du
Computer Graphics Forum (CGF), 2020.
[Paper]
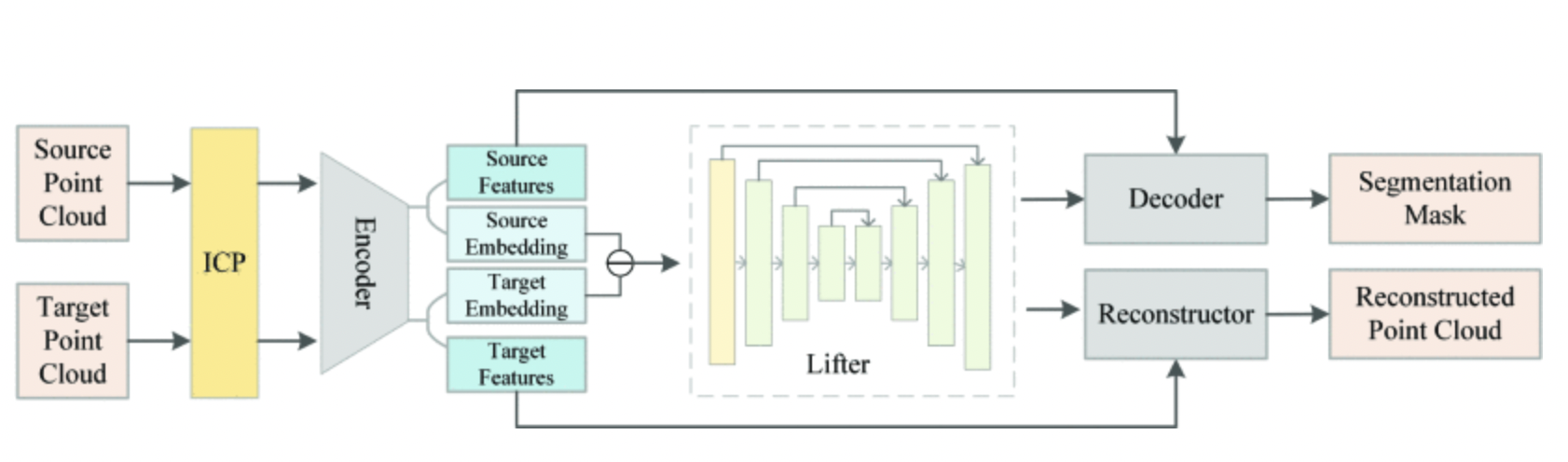
MPDNet: A 3D Missing Part Detection Network Based on Point Cloud Segmentation
Zhaoxin Fan, Hongyan Liu, Jun He, Min Zhang, Xiaoyong Du
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021.
[Paper]
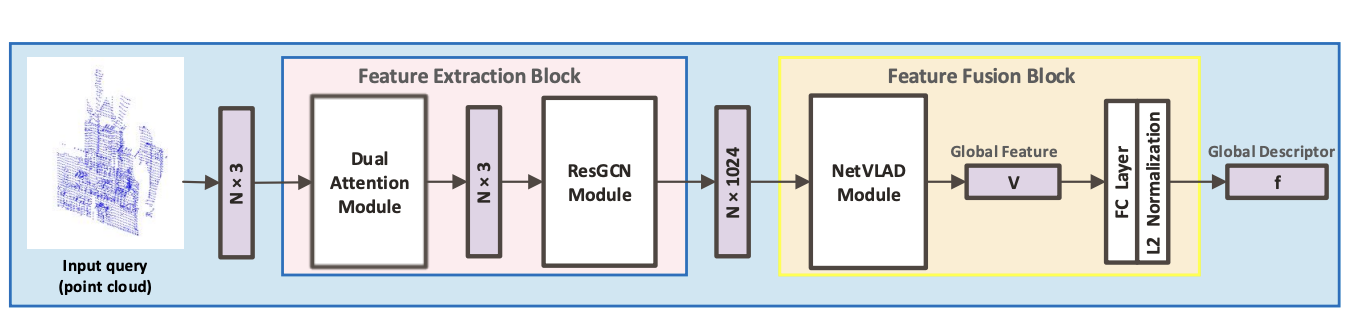
DAGC: Employing Dual Attention and Graph Convolution for Point Cloud based Place Recognition
Qi Sun, Hongyan Liu, Jun He, Zhaoxin Fan, Xiaoyong Du
ACM International Conference on Multimedia Retrieval (ICMR), 2020.
[Paper]
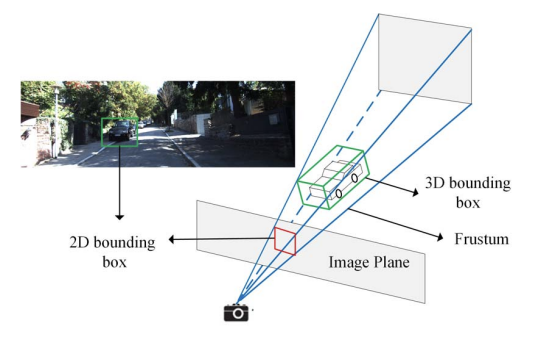
PointFPN: A Frustum-based Feature Pyramid Network for 3D Object Detection
Zhaoxin Fan, Hongyan Liu, Jun He, Siwei Jiang, Xiaoyong Du
International Conference on Tools with Artificial Intelligence (ICTAI), 2020.
[Paper]
Patents
- Chinese National Invention Patent: 一种限高装置高度检测方法和系统. 国家发明专利. CN113658226A
- Chinese National Invention Patent: 一种多视角图像的生成方法及装置. 国家发明专利. CN119625150A
- Chinese National Invention Patent: 一种基于深度估计的单目物体三维重建方法及装置. CN119784930A
- Chinese National Invention Patent: 基于视觉风格特征的多样性增强协同语音动作生成系统. 国家发明专利. CN119540034A
- Chinese National Invention Patent: 基于动态神经网络和特征调制的零样本语音克隆方法. 国家发明专利. CN119360821A
- Chinese National Invention Patent: 一种使用单目RGB图像进行虚拟人驱动的方法. 国家发明专利. CN116597509A
- Chinese National Invention Patent: 一种基于 Wav2Lip 模型视频说话人的后处理方法. 国家发明专利. 2024113137542
- Chinese National Invention Patent: 一种纹理重建方法及装置. 国家发明专利. 2024116956146
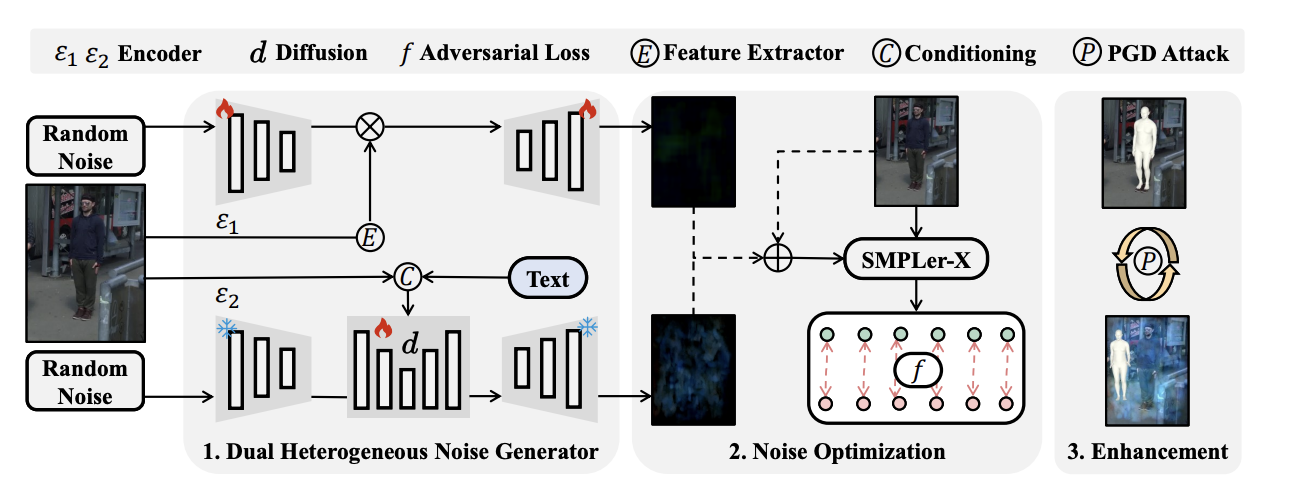
- Chinese National Invention Patent:一种提高数字人姿态估计的对抗性攻击方法及装置. 国家发明专利. 202510427766.6
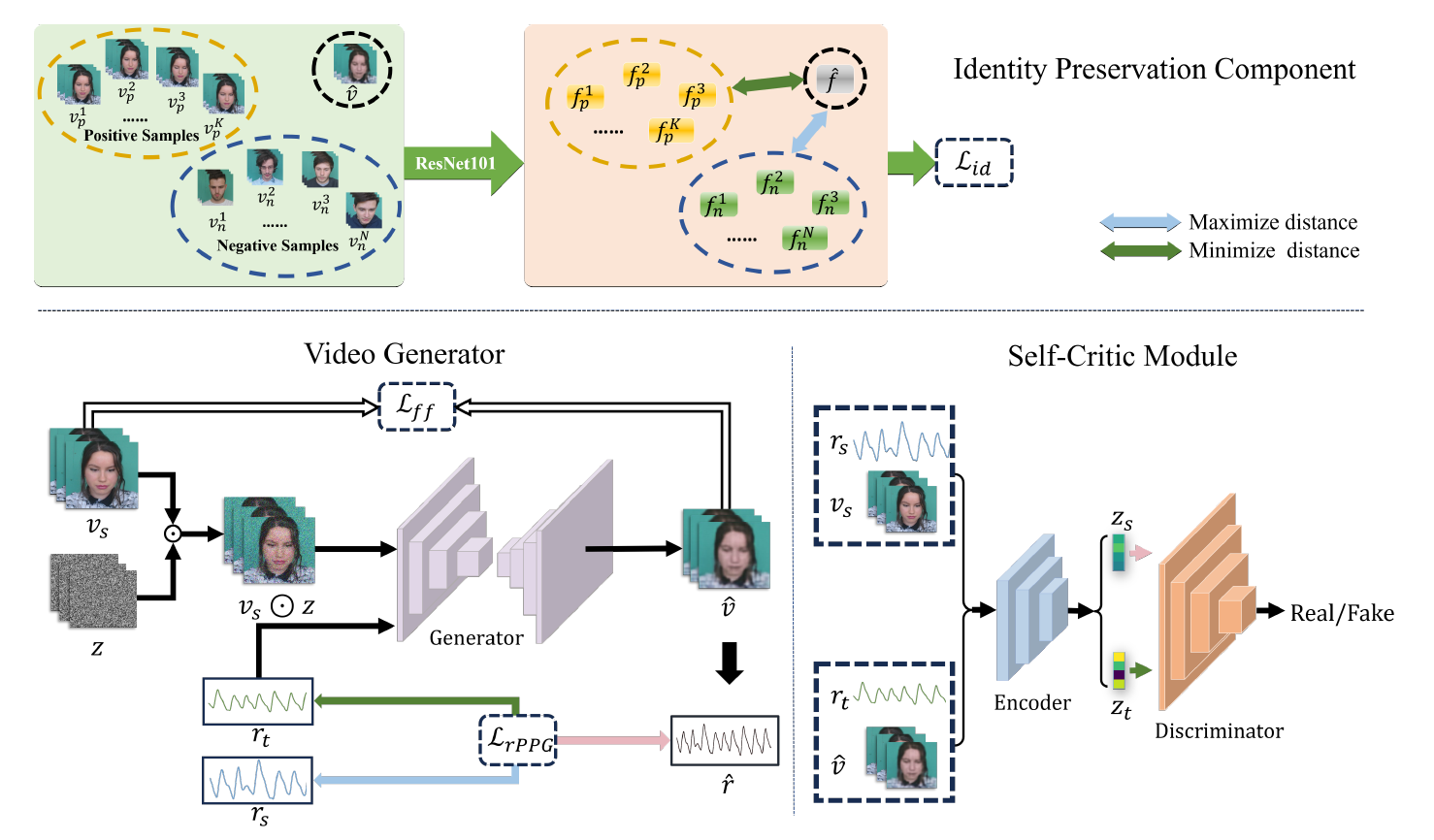
- Chinese National Invention Patent: 基于双向对偶耦合的数字人表情编辑方法. 国家发明专利. 202510654473.1
- Chinese National Invention Patent: 基于流形投影的数字人手-物协同视频生成方法. 国家发明专利. 202510654479.9